-
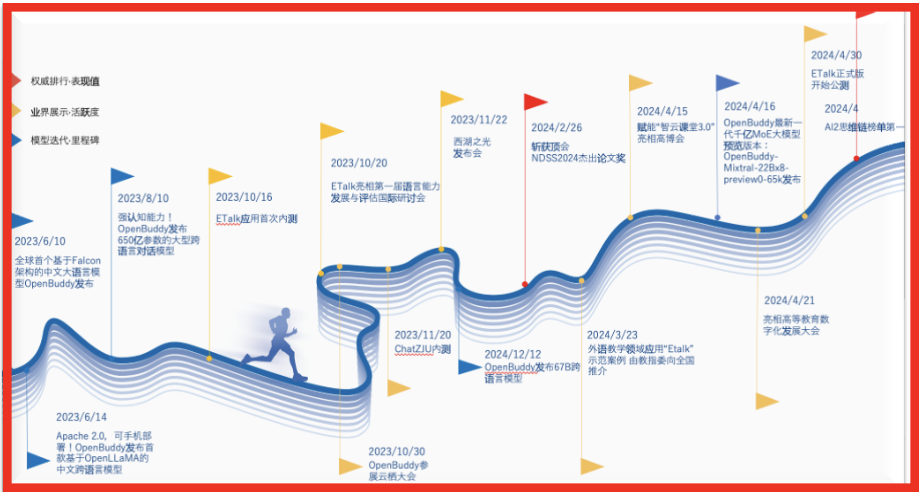 OpenBuddy系列开源模型介绍浙江大学计算机系统结构实验室(ZJU ARClab)作为项目发起者、核心贡献者,深度参与OpenBuddy模型训练和开源社区建设,并在魔搭、Hugging Face等平台上推出了OpenBuddy系列开源模型。基于Llama 3、Mixtral 22Bx8、DeepSeek等国内外优秀开源基座,OpenBuddy在模型训练过程中,重点强化了模型跨语言能力和认知能力,包括问题解决能力和深层语言理解能力。在多个基准...
OpenBuddy系列开源模型介绍浙江大学计算机系统结构实验室(ZJU ARClab)作为项目发起者、核心贡献者,深度参与OpenBuddy模型训练和开源社区建设,并在魔搭、Hugging Face等平台上推出了OpenBuddy系列开源模型。基于Llama 3、Mixtral 22Bx8、DeepSeek等国内外优秀开源基座,OpenBuddy在模型训练过程中,重点强化了模型跨语言能力和认知能力,包括问题解决能力和深层语言理解能力。在多个基准... -
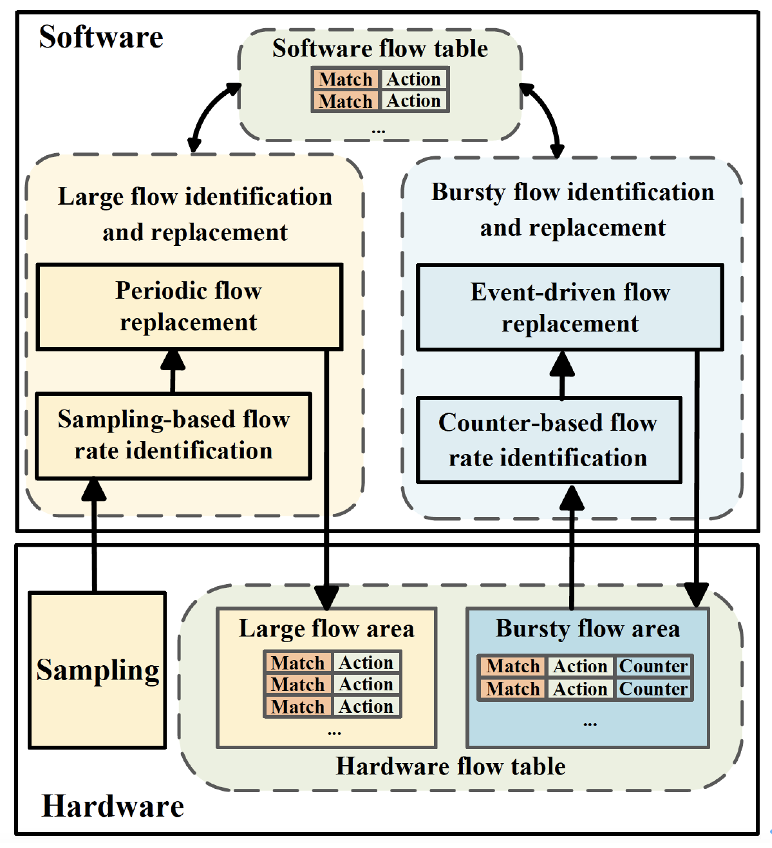 随着云网络的规模不断增长,网络容量亟待提升,需要越来越强大的网络技术支持。随着网络带宽的不断提升,云网络服务器IO性能得到飞跃式发展。而由于摩尔定律的日渐失效,云服务器处理器性能提升迟滞,其处理能力已无法满足未来云网络的需求,成为了亟待解决的性能瓶颈。为了解决这一瓶颈,业界普遍采用可编程网络设备上的专用处理器(DPU,Discrete Processing Unit)对相应的网络功能进...
随着云网络的规模不断增长,网络容量亟待提升,需要越来越强大的网络技术支持。随着网络带宽的不断提升,云网络服务器IO性能得到飞跃式发展。而由于摩尔定律的日渐失效,云服务器处理器性能提升迟滞,其处理能力已无法满足未来云网络的需求,成为了亟待解决的性能瓶颈。为了解决这一瓶颈,业界普遍采用可编程网络设备上的专用处理器(DPU,Discrete Processing Unit)对相应的网络功能进... -
 随着云计算、大数据、物联网的发展,越来越多的信息系统部署到云上,尤其是关系国计民生与企业生存的基础设施和工业信息系统,倘若这些系统中的漏洞被发现后加以利用,后果将不堪设想。传统的封堵查杀的被动防御手段,已经凸显出在技术防护方面的不足,构建主动防御体系势在必行。可信计算的发展经历了几个阶段。最初的可信1.0来自计算机可靠性,主要以故障排除和冗余备份为手段,是基于...
随着云计算、大数据、物联网的发展,越来越多的信息系统部署到云上,尤其是关系国计民生与企业生存的基础设施和工业信息系统,倘若这些系统中的漏洞被发现后加以利用,后果将不堪设想。传统的封堵查杀的被动防御手段,已经凸显出在技术防护方面的不足,构建主动防御体系势在必行。可信计算的发展经历了几个阶段。最初的可信1.0来自计算机可靠性,主要以故障排除和冗余备份为手段,是基于... -
 近年来,隐私计算成为一个快速增长的前沿科学技术。隐私计算能够在不泄露原始数据的前提下进行数据分析。隐私计算技术可以帮助医疗、金融、政企等行业的客户更好的挖掘数据价值,该市场前景广阔。多方安全计算是当前使用最为广泛的一个解决隐私计算问题的技术。然而该技术还存在着较大的性能瓶颈。特别在通用数据分析和AI场景下处理数据的效率往往几个数量级的慢于不采用隐私保护的明文运...
近年来,隐私计算成为一个快速增长的前沿科学技术。隐私计算能够在不泄露原始数据的前提下进行数据分析。隐私计算技术可以帮助医疗、金融、政企等行业的客户更好的挖掘数据价值,该市场前景广阔。多方安全计算是当前使用最为广泛的一个解决隐私计算问题的技术。然而该技术还存在着较大的性能瓶颈。特别在通用数据分析和AI场景下处理数据的效率往往几个数量级的慢于不采用隐私保护的明文运... -
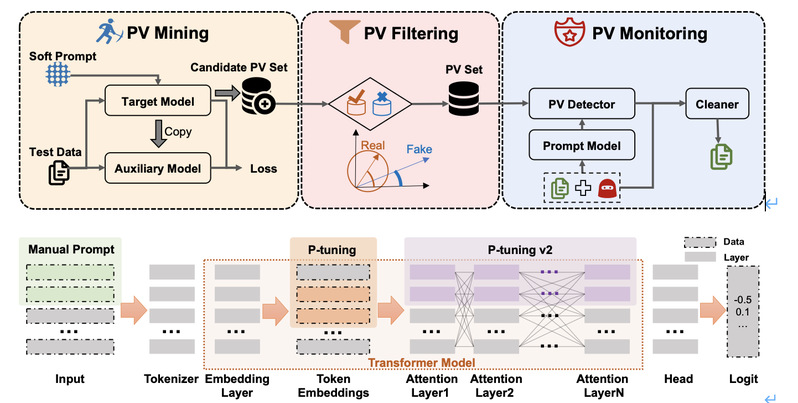 预训练语言模型(Pretrained Language Models,PLMs)已经成为了自然语言处理(NLP)的主流方法。通过在大规模文本数据集上进行预训练,这些模型可以学习到丰富的语义信息和语境知识,之后通过微调(fine-tuning)的方式适配到具体的NLP任务上,显示出强大的性能。例如,BERT、GPT系列和RoBERTa等,它们在多种NLP任务上都取得了突破性的成绩。然而,随着模型规模的增大,微调的成本也变得...
预训练语言模型(Pretrained Language Models,PLMs)已经成为了自然语言处理(NLP)的主流方法。通过在大规模文本数据集上进行预训练,这些模型可以学习到丰富的语义信息和语境知识,之后通过微调(fine-tuning)的方式适配到具体的NLP任务上,显示出强大的性能。例如,BERT、GPT系列和RoBERTa等,它们在多种NLP任务上都取得了突破性的成绩。然而,随着模型规模的增大,微调的成本也变得... -
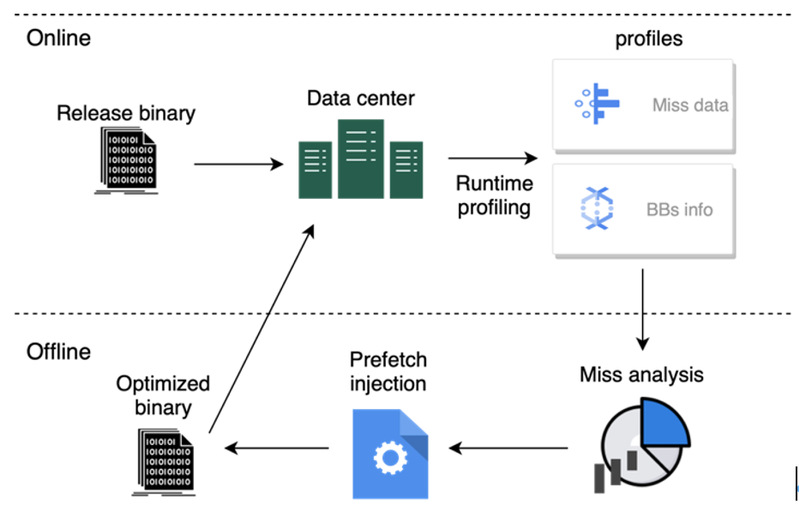 内存互联系统对业务性能影响的量化研究与优化随着摩尔定律放缓,云计算数据中心算力增长越来越需要硬件和软件协同优化,各大云计算厂商已开始自研ARM服务器芯片。而在过去二十年里,半导体技术突飞猛进,processor-memory gap持续扩大,内存访问成为了当下处理器的关键性能瓶颈。简单地提升芯片的cache容量和内存带宽并不是一个很经济和科学的解决方法,因为不同的业务具有不同的内存访问...
内存互联系统对业务性能影响的量化研究与优化随着摩尔定律放缓,云计算数据中心算力增长越来越需要硬件和软件协同优化,各大云计算厂商已开始自研ARM服务器芯片。而在过去二十年里,半导体技术突飞猛进,processor-memory gap持续扩大,内存访问成为了当下处理器的关键性能瓶颈。简单地提升芯片的cache容量和内存带宽并不是一个很经济和科学的解决方法,因为不同的业务具有不同的内存访问... -
 背景介绍可信执行环境(TrustedExecutionEnvironment,下文简称TEE)是可信计算近年新兴的解决方案,在单台计算机中通过将安全需求性高的数据和代码放入隔离的环境中,防止其遭受普通操作系统中恶意程序的攻击。相对于传统的填补系统漏洞的安全增强思路,TEE的设计是另外构建一个精简而可靠的可信操作系统,并对普通操作系统的特权等级和能直接支配的资源做出限制,在架构层面就隔离开了敏...
背景介绍可信执行环境(TrustedExecutionEnvironment,下文简称TEE)是可信计算近年新兴的解决方案,在单台计算机中通过将安全需求性高的数据和代码放入隔离的环境中,防止其遭受普通操作系统中恶意程序的攻击。相对于传统的填补系统漏洞的安全增强思路,TEE的设计是另外构建一个精简而可靠的可信操作系统,并对普通操作系统的特权等级和能直接支配的资源做出限制,在架构层面就隔离开了敏... -
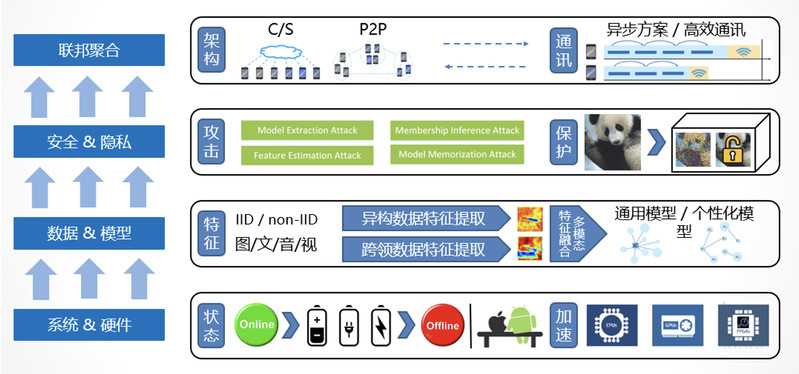
 背景介绍联邦学习(FederatedLearning,FL)提供了一种灵活的解决方式,允许机器学习应用以一种保留隐私数据在本地的方式进行分布式学习,在不违反法律和道德要求的情况下,使多个隐私数据拥有方参与合作训练共同的模型。联邦学习允许不同组织和设备共同参与训练构建机器学习模型,这些组织和设备使用的数据存储在本地。联邦学习算法在保证模型训练过程的同时不侵犯用户隐私数据,用户在本...
背景介绍联邦学习(FederatedLearning,FL)提供了一种灵活的解决方式,允许机器学习应用以一种保留隐私数据在本地的方式进行分布式学习,在不违反法律和道德要求的情况下,使多个隐私数据拥有方参与合作训练共同的模型。联邦学习允许不同组织和设备共同参与训练构建机器学习模型,这些组织和设备使用的数据存储在本地。联邦学习算法在保证模型训练过程的同时不侵犯用户隐私数据,用户在本... -
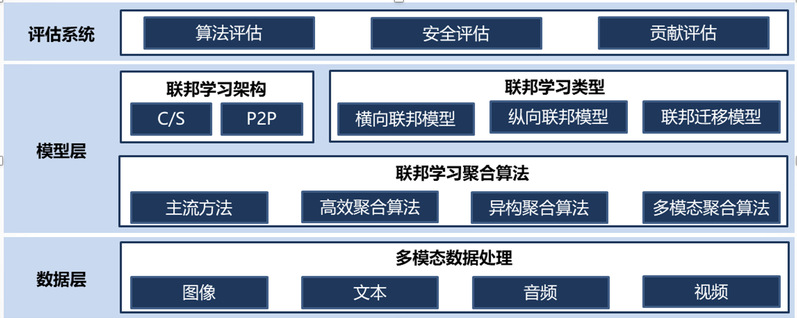
 背景介绍随着大数据、人工智能、云计算等新技术在各行业不断深入应用,全球数据呈现爆发增长、海量集聚的特点,数据的价值愈发凸显。一方面,能通过这些属于不同组织的原始数据抽取出有价值的信息,这些信息能通过机器学习技术来提升产品、服务和福利的质量;另一方面,在分布式场景下会存在潜在的滥用和攻击行为,这对数据隐私和安全提出了极大地挑战。联邦学习通过聚合本地训练的模型参...
背景介绍随着大数据、人工智能、云计算等新技术在各行业不断深入应用,全球数据呈现爆发增长、海量集聚的特点,数据的价值愈发凸显。一方面,能通过这些属于不同组织的原始数据抽取出有价值的信息,这些信息能通过机器学习技术来提升产品、服务和福利的质量;另一方面,在分布式场景下会存在潜在的滥用和攻击行为,这对数据隐私和安全提出了极大地挑战。联邦学习通过聚合本地训练的模型参... -
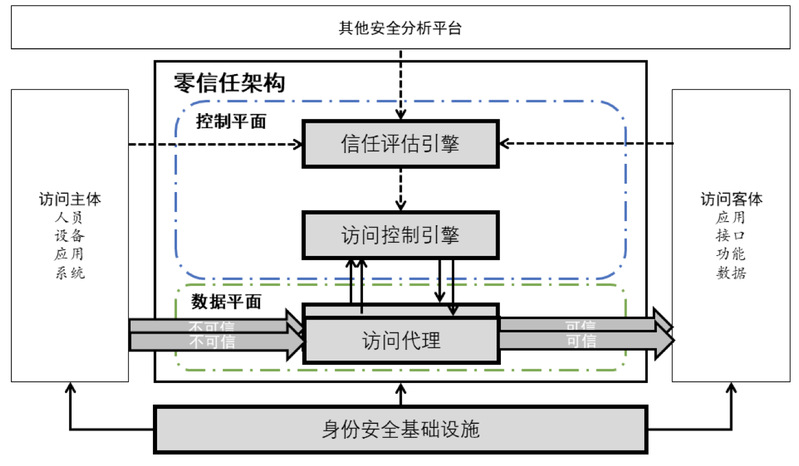
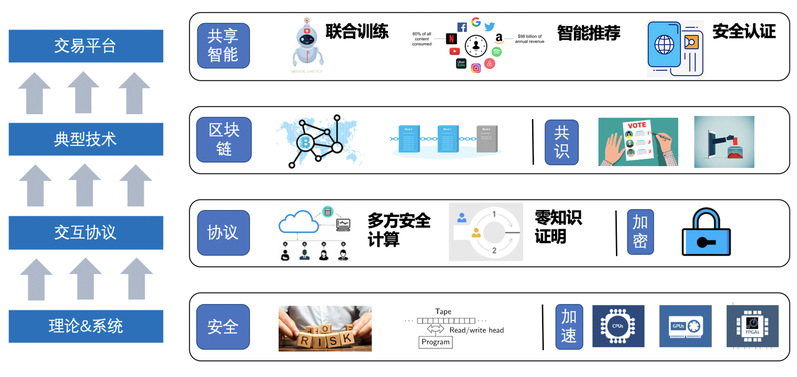 背景介绍随着深度学习等基于数据驱动的技术被广泛应用,数据已经成为了各行各业的宝贵财富。在零信任场景下,研究机构与机构之间的数据安全交易、数据联合训练、安全知识付费等功能,对促进数据共享、社会进步发展有着重要的意义。在共享学习领域,联邦学习、拆分学习等技术在一定程度上保障了用户的隐私安全。但是,目前仍存在着多种针对这些共享学习的攻击形式,如:对抗样本、投毒攻击...
背景介绍随着深度学习等基于数据驱动的技术被广泛应用,数据已经成为了各行各业的宝贵财富。在零信任场景下,研究机构与机构之间的数据安全交易、数据联合训练、安全知识付费等功能,对促进数据共享、社会进步发展有着重要的意义。在共享学习领域,联邦学习、拆分学习等技术在一定程度上保障了用户的隐私安全。但是,目前仍存在着多种针对这些共享学习的攻击形式,如:对抗样本、投毒攻击...