

联邦学习隐私计算平台数据隐私保护技术研究
背景介绍
联邦学习(Federated Learning, FL)提供了一种灵活的解决方式,允许机器学习应用以一种保留隐私数据在本地的方式进行分布式学习,在不违反法律和道德要求的情况下,使多个隐私数据拥有方参与合作训练共同的模型。联邦学习允许不同组织和设备共同参与训练构建机器学习模型,这些组织和设备使用的数据存储在本地。联邦学习算法在保证模型训练过程的同时不侵犯用户隐私数据,用户在本地挖掘数据信息的价值,最终构建和使用机器学习模型。本项目基于这一技术背景,旨在搭建一个涵盖主流机器学习与深度学习算法的联邦学习平台,解决联邦学习算法中的通信效率、系统异构、统计异构问题,同时基于对现有改进方法的大量调研和对比分析实验的基础上,总结对深度学习过程进行差分隐私改造的经验和理论结论,并提出具有超SOTA方法性能的差分隐私深度学习技术,为联邦学习计算平台保驾护航。
系统架构
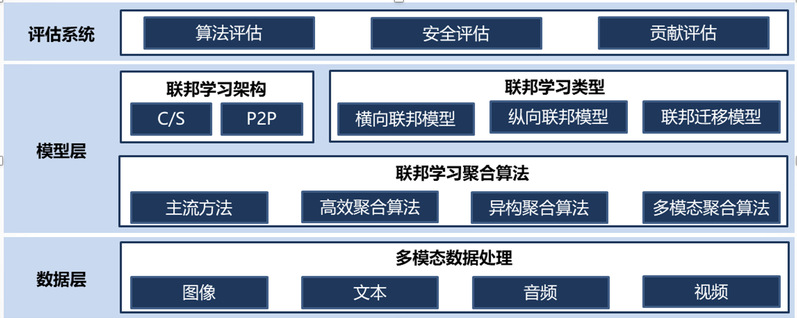
联邦学习隐私聚合算法研究

基于差分隐私的数据保护技术研究
系统特点
本项目旨在解决联邦学习隐私计算过程中面临的通讯成本较高、数据分布不均匀与数据隐私泄露风险等的热点研究问题。具体的研究:①分析现有联邦学习场景下模型聚合的实现方法与通讯开销,研究具有较少通讯成本的高效联邦聚合技术,并提供面向数据异构的保证模型精度的联邦聚合解决方案。②研究联邦学习隐私计算过程中使用的数据隐私保护技术,实现多种隐私保护技术在联邦学习场景下的安全性评估。③针对机器学习与联邦学习场景下部署的各种差分隐私算法,从模型构建的不同阶段,进行较为全面的数据隐私保护效果的性能评估度量,为联邦学习隐私计算平台的有效性、实用性提供详细的测评。
移动设备和物联网设备(IoT)正在成为全球数十亿用户的主要计算资源,这些设备会生成大量数据,可用于改进众多现有应用程序。从隐私和经济的角度来看,由于这些设备的计算能力不断增强,在本地存储数据和训练模型变得越来越有吸引力。联邦学习通过聚合本地训练的模型参数,使许多客户端能够生成全局推理模型,而无需共享本地数据。本项目以主流的联邦学习隐私算平台为出发点,针对现有联邦聚合方案无法很好的适应严格限制通讯场景的问题,提出基于anchor联邦聚合的解决方案,能够成百上千倍的降低已有通讯量,因此有望在通讯较差的情况下替代原有的聚合方案,达到降低通讯成本的目的。此外,我们利用差分隐私技术为联邦学习隐私计算平台提供了额外的数据隐私保护技术,并首次基于差分隐私对机器学习各阶段进行了隐私保护效果测试与评估,为联邦学习场景下数据隐私保护方案的优化提供了理论和实践上的指导。