

联邦学习数据隐私保护技术研究
背景介绍
随着大数据、人工智能、云计算等新技术在各行业不断深入应用,全球数据呈现爆发增长、海量集聚的特点,数据的价值愈发凸显。一方面,能通过这些属于不同组织的原始数据抽取出有价值的信息,这些信息能通过机器学习技术来提升产品、服务和福利的质量;另一方面,在分布式场景下会存在潜在的滥用和攻击行为,这对数据隐私和安全提出了极大地挑战。联邦学习通过聚合本地训练的模型参数,使许多客户端能够生成全局推理模型,而无需共享本地数据。在实践中,每个客户端的计算和通信能力可能会有很大甚至是动态变化,决配备非常不同的计算和通信能力的异构客户端至关重要。因此,我们通过提出一种全新的联邦学习聚合方案,在现有联邦学习框架的基础上,降低客户端与服务器之间的通讯成本,并提升联邦学习场景容纳异质性的能力,提升异构场景下本地客户端的模型精度。
系统架构
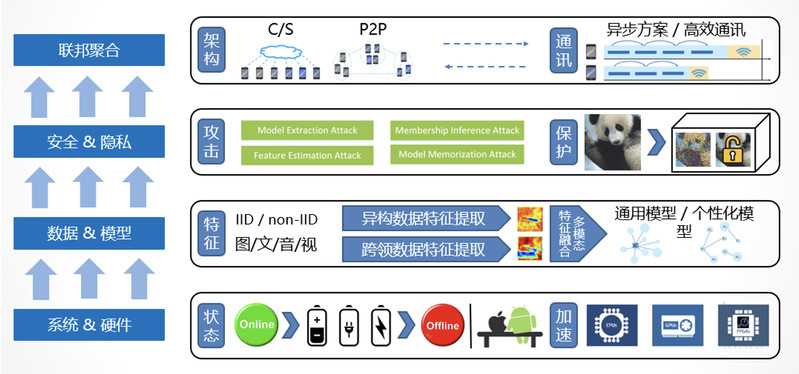
系统特点
1. 横向联邦学习场景下的高效聚合算法,通讯成本低于当前主流的SOTA算法,该算法能够兼容原型系统;
2. 实现纵向联邦学习场景下的异构聚合算法,本地模型精度高于当前主流的SOTA算法,该算法能够兼容原型系统;
3. 实现联邦迁移学习场景下的多模态数据融合算法,全局模型精度高于当前主流的SOTA算法,该算法能够兼容原型系统;
4. 应用数据隐私计算技术:差分隐私、同态加密、可信执行环境TEE的隐私训练方法,从各个方法的原理和出发点,提升算法的安全性与效率。
<<< 返回