

Buffer Filter: A Last-level Cache Management Policy for CPU-GPGPU Heterogeneous System
Buffer Filter: A Last-level Cache Management Policy for CPU-GPGPU Heterogeneous System
Abstract
There is a growing trend towards heterogeneous systems, which contain CPUs and GPGPUs in a single chip. Managing those various on-chip resources shared between CPUs and GPGPUs, however, is a big issue and the last-level cache (LLC) is one of the most critical resources due to its impact on system performance. Some well-known cache replacement policies like LRU and DRRIP, designed for a CPU, can not be so well qualified for heterogeneous systems because the LLC will be dominated by memory accesses from thousands of threads of GPGPU applications and this may lead to significant performance downgrade for a CPU. Another reason is that a GPGPU is able to tolerate memory latency when quantity of active threads in the GPGPU is sufficient, but those policies do not utilize this feature.
In this paper we propose a novel shared LLC management policy for CPU-GPGPU heterogeneous systems called Buffer Filter which takes advantage of memory latency tolerance of GPGPUs. This policy has the ability to restrict streaming requests of GPGPU by adding a buffer to memory system and vacate LLC space for cache-sensitive CPU applications. Although there is some IPC loss for GPGPU but the memory latency tolerance ensures the basic performance of GPGPU’s applications. The experiments show that the Buffer Filter is able to filtrate up to 50% to 75% of the total GPGPU streaming requests at the cost of little GPGPU IPC decrease and improve the hit rate of CPU applications by 2x to 7x.
Introduction
1) We find the reuse distance of a significant proportion of GPGPU blocks is within 1K. The proportion is 5% to 10% around.
2) We propose Buffer Filter, a shared LLC management policy, for heterogeneous CPU-GPGPU systems to filtrate the streaming requests from the GPGPU.
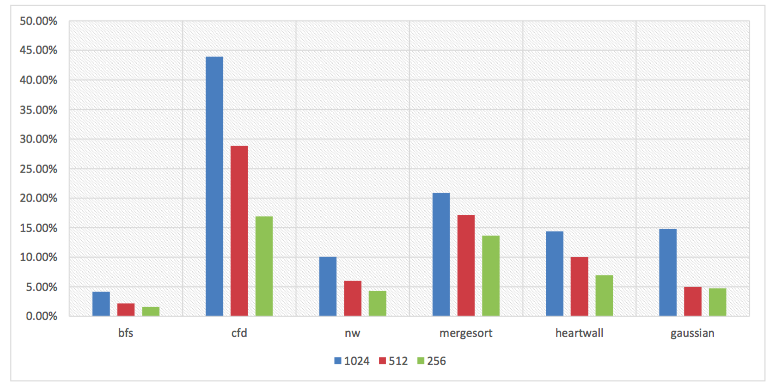
Properties of different reuse distance of GPGPU blocks
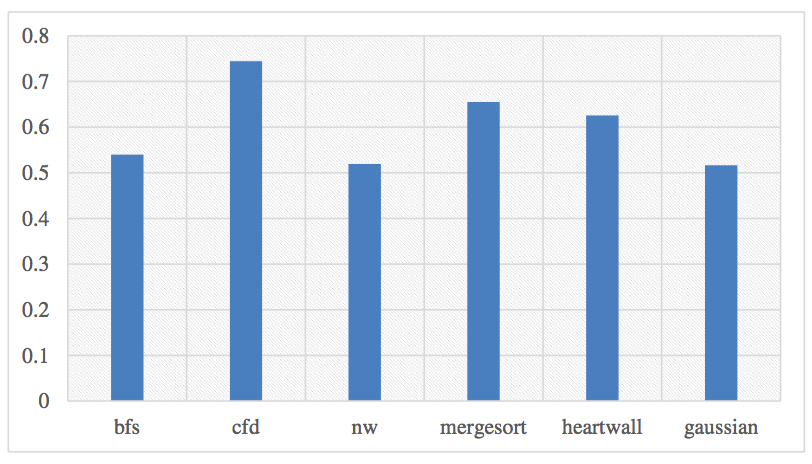
Original GPGPU miss rate without sharing LLC with CPU
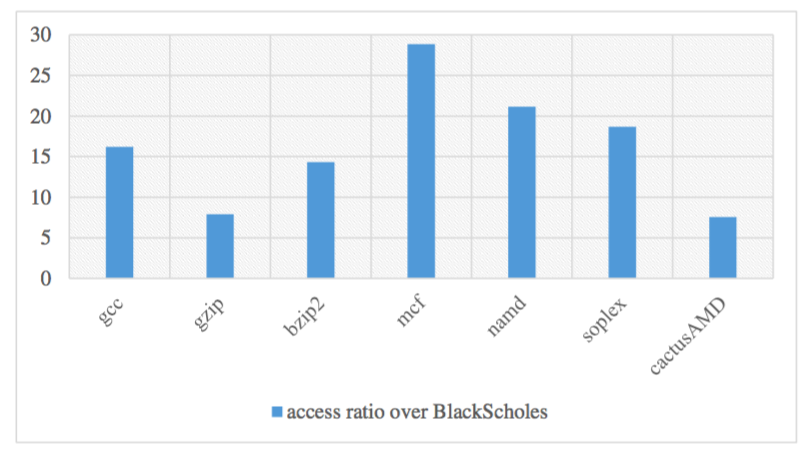
The access ratio of GPGPU to CPU
Framework
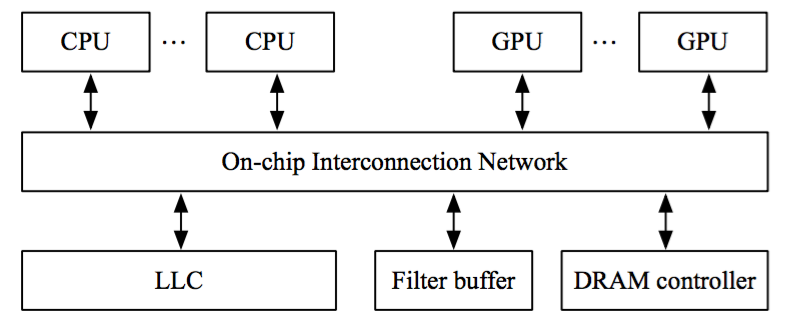
The heterogeneous architecture with filter buffer

Procedure of Buffer Filter
Results
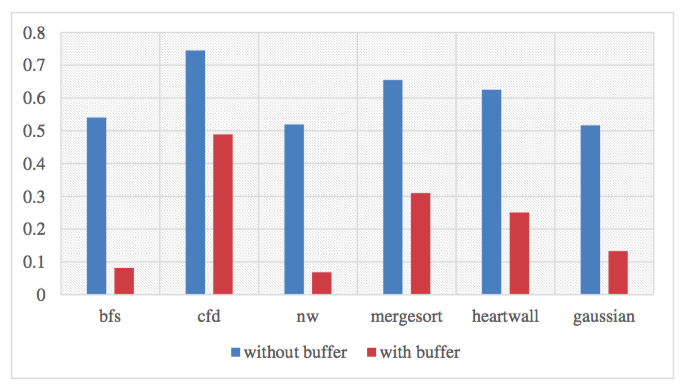
Comparison of GPGPU hit rate with and without buffer
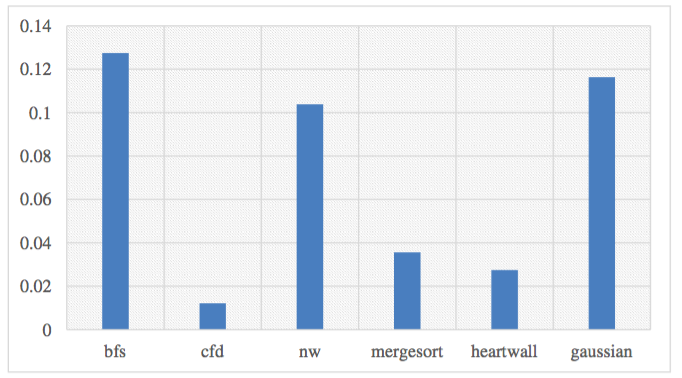
Normalized IPC drop
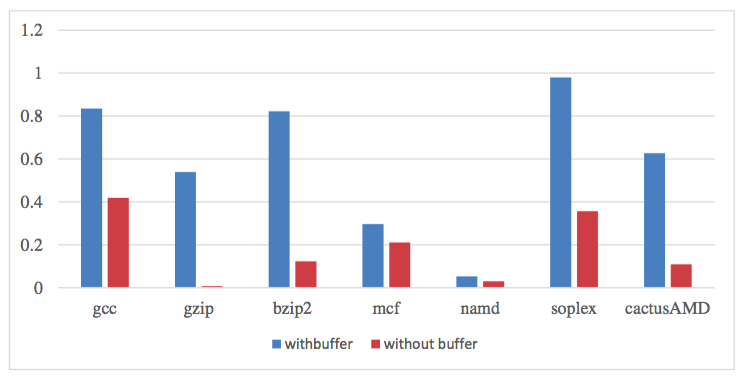
CPU hit rate by using or not using Buffer Filter
Members
Copyright Statement
This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder.