

喜讯!ARClab团队三篇论文被机器学习领域顶级会议ICML 2026录用
近日,浙江大学计算机系统结构实验室(ZJU ARClab)三篇论文同时被第43届国际机器学习大会(International Conference on Machine Learning, ICML 2026)录用。这充分展现了ARClab在人工智能前沿技术科学研究方面的创新实力与持续突破能力。
论文一“Watermaking LLM Agent Trajectories”针对大语言模型(LLM)智能体训练数据被未授权使用却难以追溯的问题,提出了首个面向智能体轨迹数据集的水印技术ACTHOOK,使数据集创建者能够对自身数据的下游使用情况进行可靠的版权验证。论文二“AugServe: Adaptive Request Scheduling for Augmented Large Language Model Inference Serving” 面向增强型大语言模型推理服务中的高效调度问题,提出了一种自适应请求调度框架 AugServe,旨在降低外部工具调用带来的排队延迟,并显著提升满足服务质量目标(Service-Level Objectives, SLOs)的有效吞吐。论文三“Dynamic Thinking-Token Selection for Efficient Reasoning in Large Reasoning Models”聚焦大推理模型(Large Reasoning Models, LRMs)在长链式推理过程中面临的KV Cache显存占用和推理计算开销问题。
会议介绍

国际机器学习大会(International Conference on Machine Learning,简称ICML)是由国际机器学习学会(IMLS)举办的机器学习领域顶级学术会议,与NeurIPS、ICLR并称为机器学习和人工智能领域三大顶级国际会议。其论文录用代表了国际同行对相关研究创新性、技术深度和学术价值的高度认可。
论文一: Watermaking LLM Agent Trajectories
第一作者:孟文龙 浙江大学计算机系统结构实验室在读博士生,主要研究方向为大语言模型安全、数据版权保护及AI隐私计算。
指导老师:陈文智 魏成坤
内容简介:
高成本智能体训练数据面临的版权追溯困境
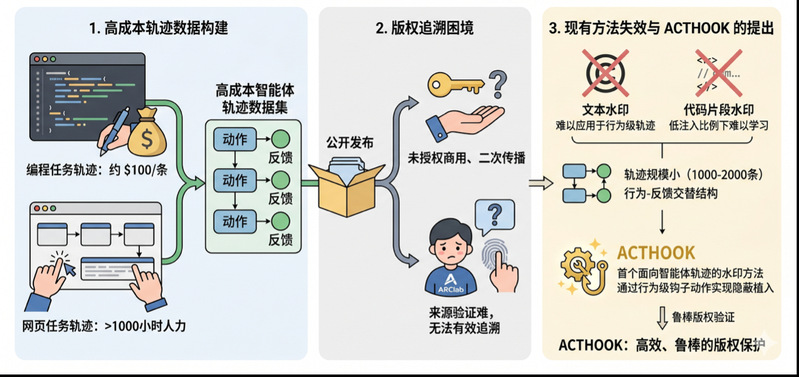
近年来,以Claude Code、OpenAI Deep Research、Microsoft Copilot为代表的LLM智能体已被广泛应用于自动化多步骤复杂任务。这类智能体的性能高度依赖于轨迹数据——即记录AI每一步操作及其反馈的顺序数据——作为训练素材。然而,构建这类数据集的成本十分高昂:编写一条高质量的编程任务轨迹平均需要约100美元的人工标注成本,某网页智能体项目为构建120个任务的数据集投入了超过1000小时的人力。一旦数据集被公开发布,创建者就难以掌握其后续使用情况,他人可能在未经授权的情况下将其用于训练商用产品,或违反许可条款进行二次传播。
现有的数据集水印方法多面向普通文本或独立代码片段,难以直接应用于智能体轨迹数据。一方面,智能体轨迹具有模型操作与环境反馈交替出现的特殊结构;另一方面,轨迹数据集的规模通常仅为1000至2000条,难以承载传统水印方法所要求的较大注入比例。如何在小规模数据中嵌入既能被模型有效学习、又不易被察觉和移除的水印,成为该领域亟待解决的关键问题。
基于行为级钩子动作的轨迹数据集水印技术ACTHOOK
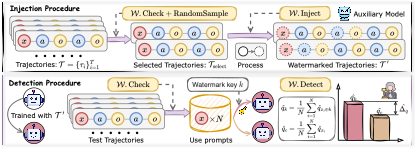
针对上述挑战,论文提出了水印框架ACTHOOK。该方法借鉴软件工程中钩子(Hook)的设计思想,在轨迹的动作边界处插入一段辅助性的钩子动作,并在用户提示中附加一段语义中性的激活密钥。在含密钥的轨迹上完成训练后,模型会建立起密钥—钩子动作之间的关联:当输入提示含有激活密钥时,模型会以显著更高的频率执行钩子动作,而正常使用场景下水印保持静默。数据集创建者可在黑盒条件下,通过对比含密钥与不含密钥两类提示下钩子动作的出现频率差异,对疑似使用其数据的模型进行版权验证。由于水印构建于行为层面而非具体token层面,且钩子动作从轨迹原有动作空间中提取,该方法对释义、摘要等改写操作具有天然的鲁棒性,也难以通过人工或规则化方式被识别和过滤。
研究者在数学推理(MATH)、网页搜索(SimpleQA)、软件工程(SWE-Smith)三类代表性智能体数据集上对ACTHOOK进行了系统评估。结果表明,在仅5%的水印注入比例下,ACTHOOK在Qwen-2.5-Coder-7B上实现了平均94.3的检测AUC,相应的Pass@1性能基本不受影响,而作为对比的代表性代码水印方法CodeMark的平均AUC仅为55.5,接近随机猜测。在面对数据过滤、释义改写、动作摘要、持续微调等多种水印移除攻击时,ACTHOOK的检测AUC仍稳定保持在85以上,验证了该方案的鲁棒性与安全性。
论文二:AugServe: Adaptive Request Scheduling for Augmented Large Language Model Inference Serving
第一作者:王瑛 浙江大学计算机系统结构实验室在读博士生,主要研究方向为大语言模型推理优化、智能体系统等。
指导老师:陈文智
内容简介:
研究动机
近年来,增强型大语言模型(Augmented Large Language Models)已成为现代智能应用的重要基础设施,能够在推理过程中调用搜索引擎、数据库、Web API 或专用模型等外部工具,以支持实时信息检索、复杂计算、网页交互和多步骤智能体任务。然而,外部工具调用使请求呈现出“生成—调用工具—等待返回—恢复生成”的多阶段执行过程,打破了传统大语言模型请求单调生成的假设,并带来动态变化的资源需求。现有推理系统通常采用 FCFS 等简单调度策略,难以感知请求执行状态和上下文处理策略的变化;当请求因工具调用而暂停时,其 KV Cache 可能被保留在 GPU、交换到 CPU,或被丢弃后等待重算,从而影响后续请求排队与资源占用,造成队头阻塞并导致 TTFT 等 SLO 违约。同时,固定的 batch-level token budget 难以适应暂停请求占用显存和可回收显存的动态变化,进一步限制系统吞吐。因此,如何同时感知请求执行状态、上下文处理策略和动态显存可用性,成为提升增强型大语言模型推理服务有效吞吐、降低延迟的关键问题。
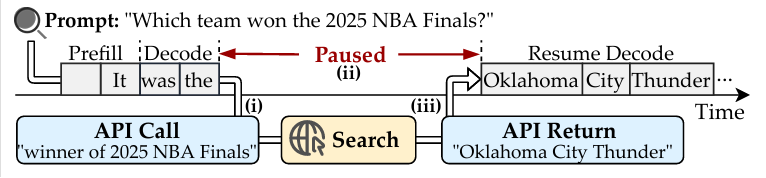
方法设计
为解决上述问题,我们提出 AugServe,一种面向增强型大语言模型推理服务的自适应请求调度框架。AugServe 将增强型大语言模型请求建模为由多个执行片段组成的动态生命周期,并根据请求所处阶段、外部调用行为、上下文处理策略和运行时反馈,联合优化请求优先级与批处理容量。
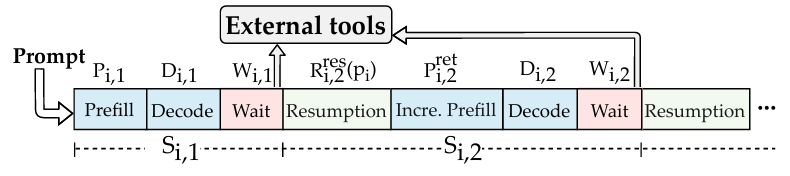
AugServe 主要包含三个模块。首先,AugServe 设计了轻量级预测模块,用于估计请求输出长度和外部调用时长,为调度提供先验信息。其次,AugServe 提出状态感知调度策略,将请求在不同阶段的资源消耗统一建模为“空间—时间成本”(space-time cost),即请求在一段时间内占用的 GPU 显存资源。基于该成本模型,AugServe 计算请求的 value density,优先调度单位资源收益更高、能够有效减少排队延迟的请求;当外部调用返回后,系统会结合实际返回长度和上下文恢复开销,动态修正后续调度优先级。最后,AugServe 设计了动态 batch-level token budget 机制,综合考虑当前 GPU 空闲显存和暂停请求中可回收的 KV Cache 显存,自适应调整每轮推理可处理的 token 数量。
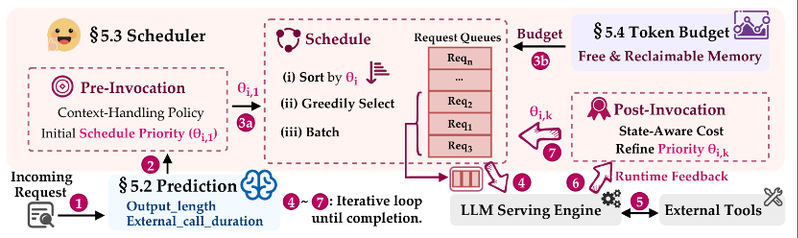
通过状态感知调度与动态 token budget 的协同设计,AugServe 能够缓解外部工具调用引起的队头阻塞,减少不必要的上下文驱逐与重算,并在高负载场景下提升 GPU 资源利用率和 SLO 满足率。
论文三:Thinking-Token Selection for Efficient Reasoning in Large Reasoning Models
第一作者:郭镇远 浙江大学计算机系统结构实验室(ZJU ARClab)在读博士生,主要研究方向为大语言模型高效推理、大模型系统与模型压缩。
指导老师:陈文智 魏成坤
论文简介:
研究动机:长思考推理带来高昂的KV Cache开销
近年来,以DeepSeek-R1等为代表的大推理模型通过显式生成推理轨迹,在数学、编程、科学问答等复杂任务中展现出更强的推理能力。然而,大推理模型在“深度思考”过程中会生成大量中间思考Token,模型必须在KV Cache中保存这些历史Token的Cache状态,以便后续生成时关注完整的上下文。随着推理链不断变长,KV Cache的显存占用和注意力计算开销会持续增加,成为推理大模型部署到资源受限场景中的关键瓶颈。现有KV Cache压缩方法多依赖局部注意力分数或人工设定的保留规则,通常适用于长上下文预填充或普通长文本生成场景,却难以准确判断哪些中间思考Token会影响未来最终答案,因此在大推理模型上往往会误删关键Token或保留冗余Token,导致推理准确率下降。

图1 不同KV Cache压缩方法的Token保留策略与推理性能对比
关键发现:少量决策关键Token决定最终答案
为理解推理轨迹中不同Token对最终答案的真实贡献,本文将模型生成内容分解为“推理轨迹”和“最终答案”,并统计最终答案Token对问题Token和思考Token的注意力贡献。实验发现,问题Token的重要性分布较为密集,而长达数千到上万Token的推理轨迹中,思考Token的重要性呈现明显稀疏性:只有约21.1%的思考Token高于平均重要性分数。进一步地,当仅保留重要性最高的约30%思考Token并让模型直接生成最终答案时,模型几乎可以恢复完整推理轨迹下的推理性能。这一现象揭示了大推理模型中的“帕累托原则”:推理链中只有20%至30%的关键思考Token像“关键节点”一样推动模型得到最终答案,而其余Token主要承担中间推导、语义衔接或局部过渡作用,对最终答案贡献小。
动态思考Token选择:让模型只记住真正重要的推理过程
基于上述发现,本文提出了DYNTS(Dynamic Thinking-Token Selection)。该方法的核心思想是在推理过程中动态预测每个思考Token对最终答案的重要性,并据此选择性保留KV Cache。与依赖已有注意力分数进行事后压缩的方法不同,DYNTS在大推理模型最后一层隐藏状态后接入一个轻量级重要性预测器(Importance Predictor)。该预测器通过答案Token对思考Token的注意力贡献作为监督信号进行训练,学习判断当前思考Token是否可能成为影响最终答案的关键Token。为了保持原模型能力,训练时冻结大推理模型主干参数,仅优化预测器。
在推理阶段,DYNTS采用由问题窗口、选择窗口和局部窗口组成的双窗口KV Cache管理机制。问题Token被视为始终重要并被完整保留;局部窗口保留最近生成的Token以维持语言连贯性;选择窗口则负责存储较早的历史思考Token。当缓存长度达到设定预算时,系统会根据预测的重要性分数在选择窗口中保留Top-k关键思考Token,并淘汰其余冗余Token。这样,模型既能持续访问真正影响最终答案的推理证据,又能避免随着推理链增长而线性累积内存和计算开销。
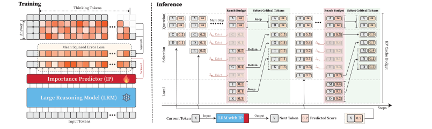
图2 DYNTS总体框架:重要性预测器训练与推理时KV Cache选择
实验结果:显著降低推理开销并保持推理准确率
本文在DeepSeek-R1-Distill-Llama-8B和DeepSeek-R1-Distill-Qwen-7B主流大推理模型上进行实验,并在AIME24、AIME25、AMC23、GPQA-Diamond、GAOKAO2023EN和MATH500六个推理基准上评估方法有效性。实验结果表明,DYNTS在所有KV Cache压缩基线中取得最佳推理性能表现。在R1-Llama上,DYNTS平均Pass@1达到61.9%,超过此前表现最好的R-KV(59.6%),并达到完整KV Cache Transformer基线的同等水平;在R1-Qwen上,DYNTS平均Pass@1达到65.3%,超过SnapKV等方法,并接近完整缓存基线65.5%的推理性能。与此同时,DYNTS在R1-Llama和R1-Qwen上分别获得约1.9倍和1.6倍平均吞吐提升,并在长解码过程中限制KV Cache增长。随着生成序列变长,标准Transformer会因缓存线性增长而出现吞吐下降和内存上升,而DYNTS通过周期性缓存选择形成可控的“锯齿形”资源曲线,峰值可达到4.51倍加速、将KV内存压缩至全缓存基线的0.19倍,并将计算开销降低0.52倍。
研究意义:推动高性能大推理模型低成本部署
DYNTS从“哪些思考Token真正影响最终答案”这一问题出发,为大推理模型的推理加速与内存优化提供了新的视角。该方法不再简单根据局部注意力或固定规则压缩缓存,而是学习预测Token对未来答案的贡献,从而更适配大推理模型“短输入、长思考、再回答”的推理范式。该研究表明,在保持推理能力的前提下,大推理模型无需记住完整的思考轨迹,只需动态保留少量关键推理证据即可支撑最终答案生成。这一结果有助于降低高性能大推理模型在实际部署中的显存门槛和推理成本,为其在边缘设备、低资源服务器和大规模在线服务中的应用提供技术支撑。