

喜讯!ARClab团队论文被国际顶级会议 DAC 2026 录用
浙江大学计算机系统结构实验室(ZJU ARClab),由陆涛、王浩宇等完成的论文《Accelerating GPU Inference of Large Language Models with Moderately Unstructured Sparse Weight Matrices》被第 63 届设计自动化会议 DAC 2026 正式录用。该论文在陈文智教授和王总辉老师指导下完成,解决中等稀疏度下大语言模型(LLM)难以在 GPU 上获得实际加速的业界难题,为低延迟大模型推理提供了全新的底层算子方案。
会议介绍

DAC 是集成电路电子设计自动化以及嵌入式系统领域的顶级国际学术会议,被中国计算机学会评定为 CCF-A 类会议。自 1964 年创办以来,DAC 一直是展示芯片设计、系统架构及软硬件协同优化最新突破的最权威舞台。其录用标准极高,要求研究在算法创新与底层硬件实现上均具备卓越的引领性。
研究背景
在大语言模型(LLM)的部署中,剪枝是减少计算开销的关键。然而,为了不损伤模型精度的中等非结构化稀疏(约 50% 稀疏度)正面临一个尴尬的现状:一是计算受限,现有的 GPU 稀疏矩阵乘法算子在处理此类稀疏度时,性能往往不及稠密矩阵乘法;二是访存瓶颈,现代 GPU 配备的高带宽显存虽然强大,但稀疏数据的不规则访问特征极易导致显存带宽浪费;三是硬件失调,传统的加速方案难以充分发挥GPU架构中 Sparse Tensor Core 的原生潜力。
方案设计
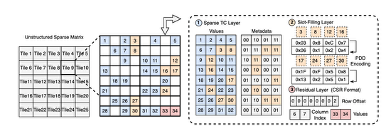
针对上述痛点,该论文提出了一种面向中等稀疏度的 GPU 高效推理方法,核心创新在于构建了三层矩阵存储与执行架构。第一是 Sparse-TC 层。通过优化数据布局,使模型能够无缝调用硬件底层的 Sparse Tensor Cores,实现计算性能的翻倍。 第二是插槽填充层。发明了基于并行差分距离的压缩算法,在极高压缩比下实现了零开销级片上解码。 第三是轻量级残余层。设计补丁机制处理非规则稀疏元素,确保了计算结果的正确性。此外,该论文设计了一套能够同时驱动 Sparse Tensor Cores 与 CUDA Cores 协同工作的混合执行流水线。
实验结论
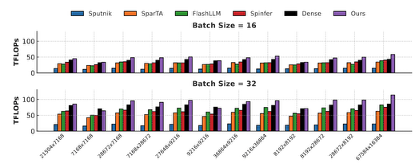
实验表明,该工作是目前首个在 HBM GPU 上,针对中等稀疏度真正跑赢稠密算子的方案。在算子突破方面,相比最先进的其他GPU实现,实现了高达 1.64 倍的内核加速;在端到端的模型推理方面,在典型 LLM 推理场景下,比 先进方案 快 1.41 倍。
作者介绍
论文作者陆涛、王浩宇均为浙江大学计算机系统结构实验室的成员,主要研究方向为高性能计算架构、系统软件等前沿方向。