

喜讯!ARClab团队论文被国际顶级会议CVPR录用
浙江大学计算机系统结构实验室(ZJU ARClab)二年级硕士生李鑫的论文《Otil: Accelerating Diffusion Model Inference via Communication-Efficient Multi-GPU Parallelism》于 2026 年 3 月被计算机视觉和模式识别领域的国际顶级会议IEEE Conference on Computer Vision and Pattern Recognition 2026(CVPR 2026)正式录用。该论文在陈文智教授和王总辉老师的指导下完成,旨在解决多GPU并行加速扩散模型推理过程中的通信开销较大问题,提出了一种多GPU并行加速扩散模型推理的高效加速方案。
会议介绍

国际计算机视觉与模式识别会议(CVPR)是IEEE一年一度的学术性会议,会议的主要内容是计算机视觉与模式识别技术,CVPR是世界顶级的计算机视觉会议。
研究动机
扩散模型已迅速成为计算机视觉领域最具影响力的生成范式之一,在图像生成、图像编辑、三维模型生成 以及视频生成等广泛任务中均展现出卓越性能。这类模型通过迭代去噪学习逆转逐步加噪过程,能够生成高度多样化且具有真实感的样本。尽管扩散模型具备出色的生成能力,但其固有的多步顺序去噪特性导致推理延迟较高。在实际部署中,并行化是在不修改原始模型前提下降低延迟的主要途径。
然而,在并行化的过程中,每一步去噪都会引入设备间通信,使得计算与通信难以有效重叠。过高的通信延迟严重限制了多 GPU 并行在 PCIe 等低带宽环境下的可扩展性,甚至可能抵消并行化带来的收益。
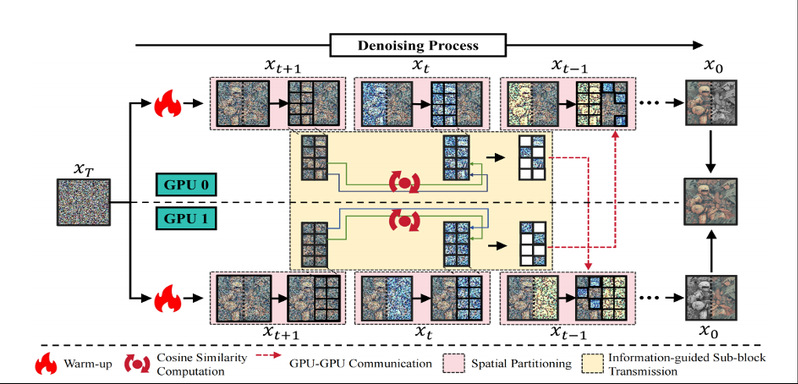
为克服上述挑战,我们提出 Otil(Only Transmit Informative Latents),一种面向扩散模型的通信高效新型并行框架。我们的核心观察是:每一步去噪的输出激活与前一步相比仅发生微小变化;且这些激活并非均匀分布,而是集中在少量空间区域。这一发现表明,无需在每次迭代后在 GPU 之间传输完整的激活值。
基于该思路,Otil 首先将激活值划分为均匀的方形子块,并将其分配到不同 GPU 上以平衡计算负载。Otil随后执行信息引导的子块传输:仅选择性地同步步间变化最大的子块,从而大幅减少 GPU 间的数据交互。为避免低变化子块被持续忽略,本我们设计动态轮询机制,在有限去噪步数内周期性遍历所有空间区域,在保持生成保真度的同时维持高通信效率。在推理阶段,Otil 将激活值均匀划分到多个 GPU,确保负载均衡,并与少步采样器完全兼容。通过上述设计,Otil 在通信开销、生成保真度与算法兼容性之间实现了有效平衡。
作者介绍
论文第一作者李鑫为浙江大学计算机系统结构实验室2024级硕士生,主要研究方向为机器学习,计算机体系结构,具身智能等。