

喜讯!ARClab团队两篇论文同时被国际顶级会议WWW 2026录用
近日,浙江大学计算机系统结构实验室(ZJU ARClab)两篇论文同时被交叉/综合/新兴领域国际顶级会议The ACM Web Conference 2026(WWW 2026)录用。论文一《Distribution-Aligned Synthetic Text Generation via Tail-Aware Enhancement》在陈文智教授与安恒信息刘博博士的指导下完成,聚焦于分布对齐的合成文本生成问题,提出了一种面向长尾语义增强的合成数据生成框架 DASGen。论文二《Boosting Large Language Models for Mental Manipulation Detection via Data Augmentation and Distillation》第一作者高袁圣是ARClab在读博士生,论文由陈文智教授和王总辉老师共同指导完成,提出了一种用于增强大语言模型精神操纵检测能力的系统性框架,并构建了一套面向真实场景的精神操纵对话数据集,为相关研究提供了重要的数据与方法支撑。
会议介绍

WWW是Web与信息网络领域最具影响力的国际顶级会议之一,同时也是中国计算机学会(CCF)认定的A类会议。会议聚焦万维网及其相关技术的前沿研究与应用,涵盖Web搜索与挖掘、信息检索、推荐系统、社交网络、知识图谱、Web安全与隐私、人机交互以及AI与Web的交叉方向等多个重要研究领域,是全球学术界与工业界研究人员展示创新成果、交流前沿思想和探讨Web未来发展的重要国际平台。
论文一《Distribution-Aligned Synthetic Text Generation via Tail-Aware Enhancement》介绍
随着生成式人工智能和大语言模型的快速发展,合成数据已成为模型训练和适配中缓解数据获取成本与隐私风险的重要手段,被广泛应用于大模型微调与下游任务优化。然而,近期研究表明,当模型在高比例合成数据条件下反复学习自身生成内容时,容易出现模型坍缩(model collapse)现象,即模型学习到的数据分布逐渐收缩,稀有但关键信息丰富的长尾语义被持续削弱,从而显著影响模型在复杂场景和长尾任务中的泛化能力。这一问题在实际应用中尤为突出:一方面,真实数据往往受到隐私保护、采集成本或合规要求的限制,难以大规模获取;另一方面,现有合成数据生成方法多侧重于表层多样性,难以系统性覆盖真实数据分布中被长期忽视的稀疏语义区域,导致生成数据在语义层面与真实分布逐渐偏离。如何在不增加额外隐私风险和计算成本的前提下,从数据生成阶段有效缓解分布收缩、增强长尾语义覆盖,成为合成数据研究中亟待解决的关键问题。
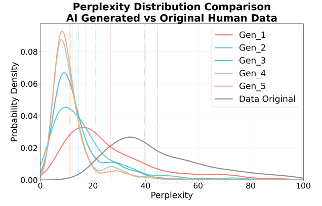
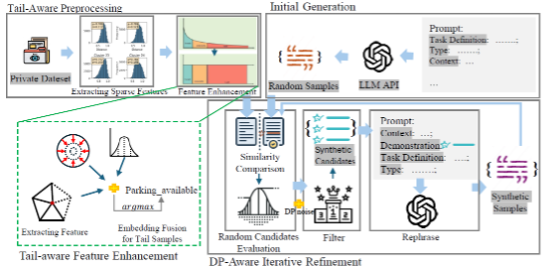
基于上述动机,该工作聚焦于分布对齐的合成文本生成问题,提出了一种面向长尾语义增强的合成数据生成框架 DASGen。该方法通过识别真实数据分布中长期被忽视的稀疏语义区域,并在生成阶段定向补全这些长尾语义,从而提升合成数据的语义覆盖度与多样性,降低模型坍缩风险并增强下游模型的泛化能力。具体而言,DASGen 在嵌入空间中对真实或参考数据进行轻量级分析以定位长尾语义区域,并在无需微调模型的前提下,引导大语言模型生成分布对齐的合成文本。该方法模型无关、部署成本低且隐私友好,为大规模合成数据场景下的模型训练提供了切实可行的技术路径。
论文二《Boosting Large Language Models for Mental Manipulation Detection via Data Augmentation and Distillation》介绍
社交媒体中的精神操纵行为对个体心理健康以及在线交互生态的完整性构成了一种隐蔽但严重的威胁。然而,由于训练数据难以标注、该类行为具有高度隐蔽性和多轮交互特征,以及缺乏真实世界数据集,对精神操纵的自动化检测面临着显著挑战。
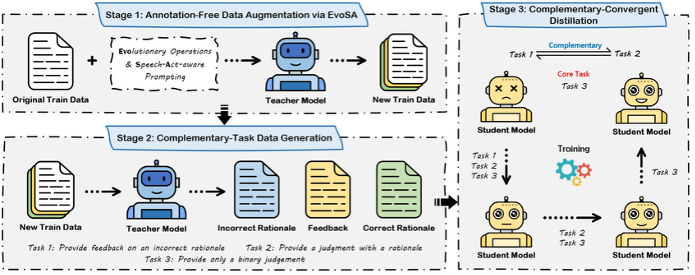
所提MentalMAD的整体框架
为应对上述问题,本文提出了一种用于增强大语言模型精神操纵检测能力的整体框架MentalMAD。该方法包含三个关键组成部分:EvoSA,一种将进化操作与具备言语行为感知能力的提示机制相结合的无需标注数据增强方法;由教师模型生成的互补任务监督信号;以及互补收敛式蒸馏策略,通过分阶段训练将精神操纵检测的推理过程逐步迁移至学生模型中。此外,本文构建了ReaMent数据集,包含5000条来源于真实世界的对话数据。大量实验结果表明,与当前最强基线方法相比,MentalMAD 在准确率上提升了14.0%,在宏平均F1分数上提升了27.3%,在加权F1分数上提升了15.1%。