

喜讯!ARClab团队论文被网络与通讯领域顶级会议INFOCOM 2026录用
浙江大学计算机系统结构实验室(ZJU ARClab)一年级博士生袁新宇的论文《LMTE: Putting the “Reasoning” into WAN Traffic Engineering with Language Models》于 2025年 12月被计算机网络领域国际顶级会议 IEEE International Conference on Computer and Communications 2026(INFOCOM 2026)正式录用。该论文在陈文智教授的指导下完成,首次将大语言模型(LLM)的预训练知识与推理能力引入广域网流量工程(WAN TE)与软件定义网络(SDN)的管理与优化中,为相关问题的建模与求解提供了系统性的理论分析与实践支撑。
会议介绍

INFOCOM是由 IEEE主办的计算机网络与通信领域的重要国际学术会议,在体系结构、网络协议与系统等方向具有深刻的历史影响力,与 NSDI、MobiCom、SIGCOMM等会议并列CCF网络领域A类会议,被认为是计算机网络领域的代表性高水平会议之一。INFOCOM对论文质量与创新性要求较为严格,强调扎实的理论基础、明确的问题建模以及完整的实验或系统验证。INFOCOM 2026共收到 1740篇投稿,接收329篇,整体录取率仅为 18.9%。
研究目标与动机
随着网络流量的持续增长,数据中心和广域网越来越依赖流量工程来优化流量。在实际部署中,TE通常需要提前计算并下发路由配置,其决策结果往往在未来一段时间内持续生效。因此,如何在存在显著需求不确定性的条件下制定稳健的流量工程方案,成为 WAN TE中的核心挑战之一。然而,真实网络流量具有明显的非平稳性和突发性,短时间内的流量激增可能导致既定路由方案迅速失效。理想的流量工程机制应当在保证常规场景下高效性的同时,对突发流量具备足够的鲁棒性。 但现有方法往往难以在这两者之间取得平衡:基于优化的方案在建模复杂不确定性时能力受限,而基于学习的方法则普遍依赖历史分布假设,在流量模式发生变化时泛化能力不足。因此,如何在不显著增加计算与运维成本的前提下,使流量工程策略兼顾常规性能与突发鲁棒性,仍是一个尚未充分解决的重要研究问题。
LLM for TE, Why—LLM的TE适用性理论分析
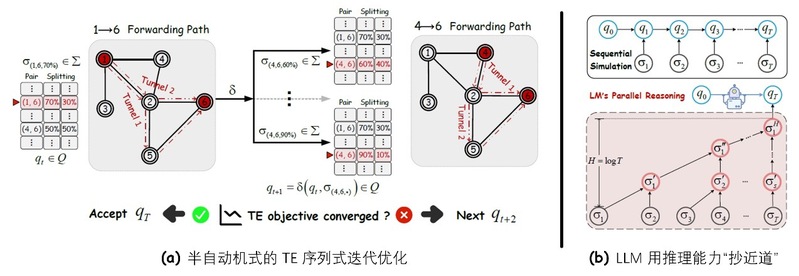
自动机视角的TE问题建模与LLM优化
为何将大语言模型引入广域网流量工程?大语言模型通过在大规模语料上的预训练,已展现出超越自然语言处理任务的强泛化能力,近期研究也表明其可迁移至多种网络系统任务。这些进展表明,LLMs同样具备应用于广域网流量工程的潜力。不仅基于经验观察,本文从理论上论证了 LLMs在 TE中的适用性。我们的核心观点是:尽管 TE属于 NP-hard问题,但其本质可被建模为一个可求解的序列决策过程(即自动机),而这一过程正是推理能力能够发挥优势的场景。进一步地,我们表明,在数据足够多样的条件下,现成的 LLMs能够以对数级深度近似从任意网络状态到近最优 TE配置的映射。 从而将复杂优化过程抽象为高层次的推理步骤。这一特性凸显了 LLMs在 WAN TE中的适配性与潜在优势。
LLM for TE, How—基于LLM的TE框架设计
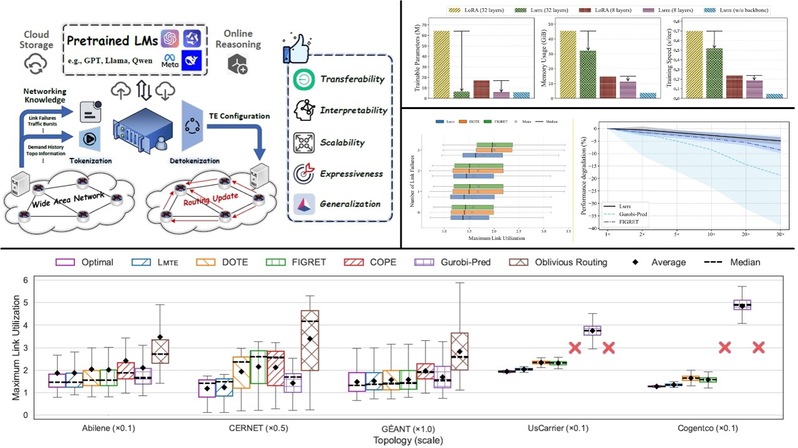
LMTE 把泛化和推理能力带入WAN TE 任务
如何将大语言模型应用于广域网流量工程?尽管理论分析表明,标准的大语言模型在形式上具备解决流量工程问题的能力,但直接应用仍面临两方面挑战:一是网络拓扑与流量需求等输入模态与自然语言存在显著差异;二是对模型进行直接微调在计算成本和泛化能力方面均不具备可行性。为此,本文提出 LMTE,一种面向流量工程优化的高效大语言模型适配框架,在保留预训练知识的同时实现轻量化定制。LMTE通过跨注意力机制将多模态网络输入与原型文本表示对齐,引导模型逐步理解流量工程任务;并结合领域感知的提示设计与可扩展的按路由器分配机制,实现仅约 1%可训练参数的高效适配。大量实验结果表明,LMTE在多种真实与合成网络场景下均显著优于现有方法,在最大链路利用率、鲁棒性以及运行效率方面均取得明显提升。
作者介绍
论文第一作者袁新宇为浙江大学计算机系统结构实验室2025级博士生,主要研究方向为机器学习,网络测量,网络管理和优化等。