

喜讯!ARClab团队论文连续4年被体系结构顶会HPCA录用
浙江大学计算机系统结构实验室林溢泉的论文“I-POP: Ignite Positive Prefetchers”于2025年11月被体系结构领域CCF-A类顶会HPCA2026录用。之前团队已经有三篇论文分别被HPCA2023, HPCA 2024,HPCA2025录用。
今年这篇论文由陈文智教授和王总辉老师指导,分析了现代高性能处理器中多预取器协同管理的必要性,揭示了现有方案的局限性,并提出一种高性能、低开销的预取器管理方案I-POP。I-POP 引入“预取有效性”这一新指标,精准量化预取行为对系统性能的净收益,并据此动态调控各预取器的开关状态与激进程度,从而有效释放预取潜力,显著提升整体性能。
会议介绍

High-Performance Computer Architecture (HPCA)是由IEEE举办的计算机体系结构领域的顶级会议,与ISCA、MICRO、ASPLOS并称为计算机体系结构领域的“四大顶会”,被视作国际前沿芯片架构研究的风向标。本次HPCA2026共收到602篇投稿,接收了119篇投稿,录用率仅19.8%。
论文解读
现代高性能处理器中通常同时集成了多种类型的硬件预取器,以扩大可识别模式的范围,覆盖更多的缓存缺失。然而,这种设计在提升潜力的同时,也带来了显著副作用:大量无效预取不仅浪费宝贵的内存带宽,还可能因缓存污染和资源竞争而降低系统性能。实验表明,在某些工作负载下,未经管理的多预取器系统反而会导致高达 24.3% 的IPC下降;而引入有效的管理机制,则可带来最高 22.6% 的IPC提升,并在预取效果不佳时及时“止损”。因此,动态、选择性地激活预取器,已成为充分发挥其性能潜力的关键所在。
现有预取器管理方案的局限
针对预取器管理方案,当前业界的研究主要分为三类,但均存在明显缺陷:(1)静态方案:为各预取器预设固定优先级,仅采纳最高优先级预取器的预测结果。虽然实现简单,但缺乏运行时反馈机制,无法适应工作负载变化;即使低优先级预取器表现更优,也无法被启用,灵活性严重受限。(2)基于强化学习的方案:利用在线学习调整策略,但计算与存储开销巨大,难以在芯片设计中落地。更重要的是,其策略调整存在显著滞后——当访存模式突变时,系统需经历较长适应期,导致性能下降。(3)基于性能计数器的方案:依赖如准确率、覆盖率等单一指标指导决策。然而,这些指标与实际 IPC 性能相关性弱,甚至出现负相关,无法真实反映预取对系统性能的净影响。而且,其决策机制通常依赖固定的阈值比较或 Top-K 选择策略,而最优阈值或 K 值会随工作负载特征和 DRAM 带宽动态变化,导致在实际运行中频繁产生次优甚至有害的控制决策。
I-POP:一种高性能、低开销的预取器管理方案
针对上述问题,本文提出 I-POP,一种高性能、低开销的多预取器管理方案。I-POP引入了一种全新的运行时指标——预取有效性(PE)。PE 统一量化预取行为的三种影响:(1)正面效益:准确且及时的预取减少缓存缺失,提升性能;(2)负面代价一:预取引发缓存污染,驱逐有用数据,造成额外的缓存缺失;(3)负面代价二:预取请求与常规需求访问竞争共享资源,增大缓存缺失的代价。通过将上述效应聚合为一个可解释、可比较的标量分数,PE 精准刻画了预取对整体性能的净贡献。实验证明,PE 与 IPC 高度正相关,并提供直观的控制信号:PE > 0 表示有益,应启用;PE ≤ 0 表示有害,应禁用。
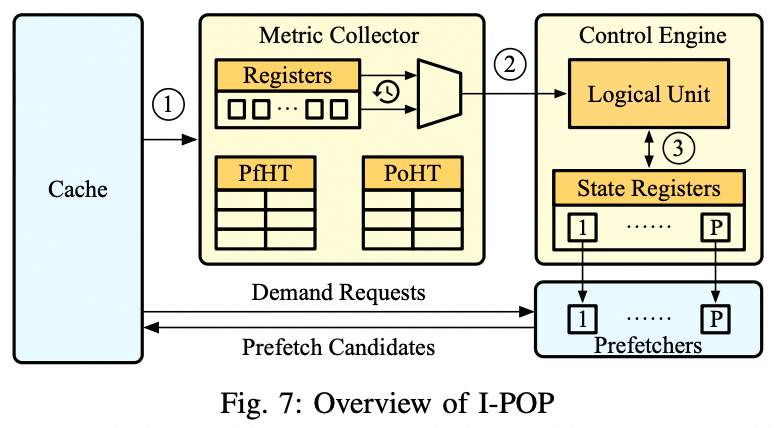
为高效实现 PE 的计算与应用,I-POP 设计了两个轻量级硬件组件:(1)指标收集器:实时追踪每个预取请求的收益与代价,周期性计算各预取器的 PE 值;(2)控制引擎:基于每个预取器的 PE 值,动态管理他们的开/关状态和激进程度。它会“点燃” PE 值为正的预取器,使其保持激活状态,并根据平均 DRAM 延迟和其他预取器的 PE 自适应地调整其激进程度。PE 值非正的预取器会被立即禁用,避免性能损失。当 DRAM 带宽相对充裕时,控制引擎会“试启”被禁用的预取器,给予其重新贡献的机会。
实验结果表明,I-POP在多种典型工作负载下均显著提升系统性能,与业界常见的PC-Stride 预取器和基本节流机制方案相比,平均IPC提升了 9.7%;与其余两种最先进方案 Bandit 和 Alecto相比,单核性能平均IPC领先 3.5~4.2%,多核性能平均IPC领先8.4~8.6%。此外,I-POP 仅需 1.46 KB 的极低存储开销,易于集成到现有处理器架构中。
作者介绍
论文第一作者林溢泉为浙江大学计算机系统结构实验室(ZJU ARClab)的在读博士生,主要研究方向为CPU微架构性能优化。