

喜讯!ARClab团队论文被人工智能顶级会议ICCV 2025录用
2025年6月,浙江大学计算机系统结构实验室(ARClab)的论文“An Inversion-based Measure of Memorization for Diffusion Models”被人工智能与计算机视觉顶会IEEE/CVF International Conference on Computer Vision (ICCV)录用。该论文由陈文智教授和王总辉老师指导,提出了一种针对扩散模型的记忆风险度量方法,通过将输入图像逆向为诱导其生成的敏感输入分布,准确充分地量化扩散模型生成任意图像的可能性,提供了一种有效的扩散模型安全性审计工具。
会议介绍

国际计算机视觉大会ICCV是由IEEE和CVF联合主办的计算机视觉领域的顶级国际会议,涵盖计算机视觉、图像处理、模式识别、机器学习等相关领域的前沿研究。ICCV为中国计算机学会(CCF)推荐A类会议,其学术水平和国际影响力在人工智能领域首屈一指。
论文介绍
扩散模型近几年来已经成为图像生成的主流方法,表现出令人惊异的图像生成能力。然而扩散模型存在记忆训练数据的风险,其中包含大量的受版权保护的数据和隐私数据。分析扩散模型记忆问题对于提升模型泛化性,保护训练数据版权与隐私具有重要意义。现有研究在大量随机生成的图像中发现高度记忆的图像,并且在随机生成时直接利用扩散模型训练集中的图像标题作为提示,这种方式对于理解记忆程度是不充分的。
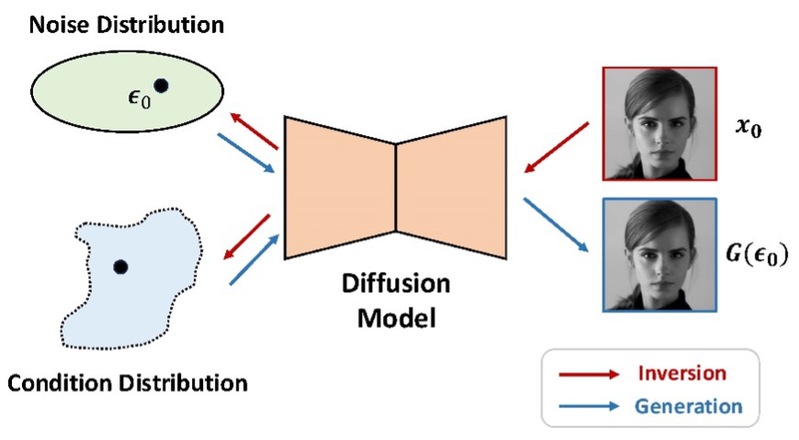
针对此问题,本文提出了基于逆向的扩散模型记忆度量方法InvMM (Inversion-based Measure of Memorization)。InvMM将给定图像逆向为诱导扩散模型原样将其生成的敏感随机噪声分布,如果是文生图模型则额外逆向一个条件分布。来自分布中的样本将以100%的概率重复生成给定图像。在逆向得到的敏感噪声分布之上,本文定义了记忆程度的量化指标,其大小反映了扩散模型生成给定图像的可能性。为了确保逆向的敏感噪声分布尽可能紧凑地拟合真实的敏感噪声分布,本文提出了一个自适应的优化算法,以避免度量结果的高估和低估问题。

本文在多个数据集和扩散模型上验证了InvMM的有效性,结果表明InvMM能够准确地度量不同图像的记忆差异,并发现了新的高度记忆图像,这些图像能够被潜在的对抗性提示生成,但无法被其训练集中的标题生成。InvMM的设计原理明确了记忆和成员推断(是否在训练集中)这两个概念的本质区别:记忆建立在感知层尺度,而成员推断建立在统计学尺度。记忆与成员之间没有必然的联系,存在训练集外的图像记忆程度大于训练集图像。相比于成员推断,InvMM描述特定图像被生成的风险,不局限于训练集内的风险。
作者介绍
论文第一作者马哲是浙江大学计算机系统结构实验室(ARClab)博士生,主要研究方向为人工智能安全。