

喜讯!ARClab团队两篇论文同时被USENIX Security 2025录用
2025年6月,浙江大学计算机系统结构实验实验室(ZJU ARClab)两篇论文同时被网络安全领域CCF-A类会议USENIX Security 2025录用。论文一“GradEscape: A Gradient-Based Evader Against AI-Generated Text Detectors”的第一作者是ARClab在读博士生孟文龙,指导老师是陈文智教授和魏成坤老师,论文提出了一种针对AI文本检测器的新型对抗攻击方法。论文二“PRSA: Prompt Stealing Attacks against Real-World Prompt Services”的第一作者是ARClab在读博士生杨勇,指导老师是陈文智教授和王总辉老师,该论文提出了一种针对现实世界提示词服务的提示词窃取攻击方法。论文的录用凸显了ARClab团队在推动大模型技术进步以及解决大模型安全的实际问题方面的努力和贡献。
会议介绍

USENIX Security Symposium(USENIX Security)是计算机安全与隐私保护领域的国际顶级学术会议,由美国USENIX协会主办。该会议是全球计算机系统安全、网络安全及相关领域最具影响力的学术论坛之一,聚焦于系统安全、网络防护、隐私保护、密码学与人工智能安全等前沿方向的交叉研究。USENIX Security被中国计算机学会(CCF)认定为信息安全领域的A类会议,同时也是网络与系统安全领域公认的“四大顶会”之一。
论文一“GradEscape: A Gradient-Based Evader Against AI-Generated Text Detectors”
论文提出了逃避器的概念,AI生成的文本在经过逃避器修改之后可以绕过AI文本检测器的检测,同时保持自身的语义。GradEscape借鉴图像领域中机遇梯度反馈的对抗攻击方法,利用检测器的梯度更新逃避器模型的参数,从而使逃避器用最少的更改实现攻击的目标。
AI文本检测器与GradEscape应用场景
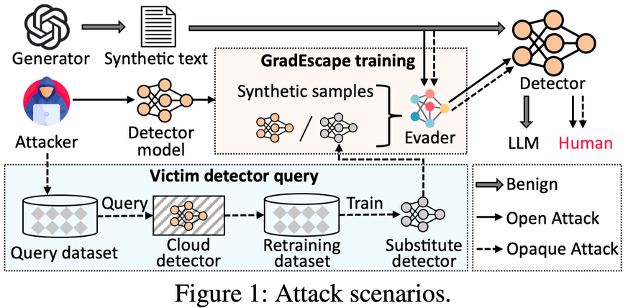
在当前大模型生成内容(如ChatGPT)广泛应用的背景下,AI文本检测器被用于区分人工撰写与AI生成的文本。攻击者可利用生成器产生合成文本,尝试绕过检测器模型。GradEscape是一种针对AI文本检测器的对抗攻击训练框架,能够通过对合成样本的训练,生成专门用来规避检测器的“逃避器”模型,实现对检测器的攻击。如图所示,攻击者可以通过不同场景对AI文本检测器发起攻击。对于开放攻击,攻击者可以直接访问检测器模型,基于合成文本优化逃避器,使其生成更难被检测的文本。对于不透明(Opaque)攻击,攻击者无法直接访问目标检测器,而是通过云检测器接口查询,将结果反馈用于构建重训练数据集,并训练替代检测器,从而间接实现绕过。
逃避器训练流程
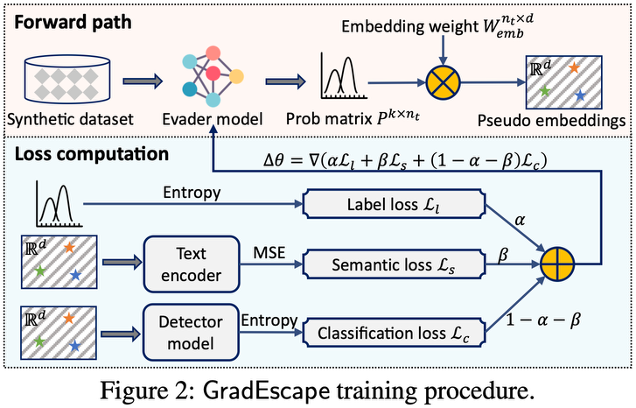
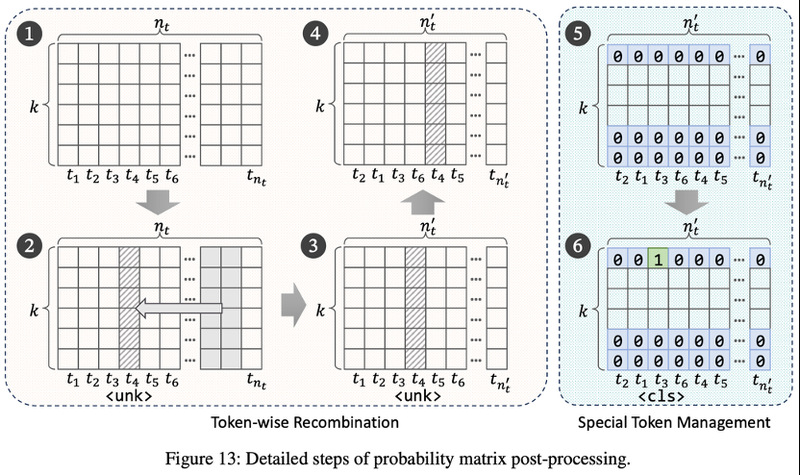
GradEscape 的逃避器训练流程包含前向路径和损失计算两大核心部分。在前向路径中,首先利用合成数据集输入到逃避器模型,生成每个token的概率分布矩阵。该概率矩阵与嵌入权重结合,得到伪嵌入向量,为后续损失计算提供基础。损失计算阶段,系统融合三类损失以优化逃避器参数:第一,标签损失,基于概率分布的熵度量,鼓励模型输出与目标标签一致;第二,语义损失,通过伪嵌入向量输入文本编码器,用均方误差保持生成文本与原始文本在语义空间的一致性;第三,分类损失,伪嵌入通过检测器模型,基于熵度量检测器对生成样本的判别结果。最终,三类损失以加权方式共同作用,驱动逃避器模型参数的更新,提升逃避效果。此外,在生成概率矩阵后,还会对词元顺序进行重组,并针对特殊符号(如未知符、分类符等)进行专门管理,保证躲避器的输出能正确输入到检测器中。GradEscape可以在仅使用139M参数量的条件下获得超过11B baseline的攻击成功率。
论文二 “PRSA: Prompt Stealing Attacks against Real-World Prompt Services”
设计了一个实用的攻击框架PRSA,结合提示词生成与剪枝机制,在仅依赖极少输入-输出对的情况下,精准推理出目标提示词并生成功能等效的盗版提示词。此外,论文还从互信息的角度分析了攻击为何有效,为提示词安全性评估和防护机制设计提供了新的理论视角。
研究背景:随着大语言模型能力的持续增强,围绕提示词(Prompt)的商品化服务快速发展。开发者可以在提示词交易市场(如PromptBase)出售用于特定任务的提示模板,或通过将提示词封装进应用,发布至LLM应用商店(如OpenAI GPT Store),构建具备特定功能与交互风格的模型应用。这类提示词服务已成为推动LLM应用落地的关键机制,也催生出对提示词本身的高商业价值依赖。
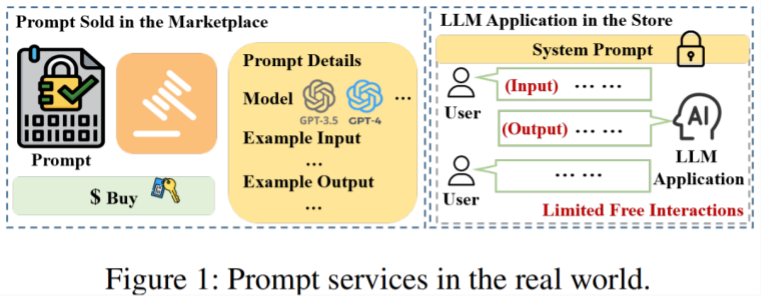
然而,这些高质量提示词也成为攻击者的目标。PRSA正是在这一背景下提出,针对两类主流提示词服务场景展开攻击:一是在提示词交易市场中,通过公开展示的输入输出示例,重构售卖的提示词;二是在LLM应用商店中,通过有限的免费交互,重构内置的系统提示词。PRSA在无需直接访问提示词内容的情况下,即可重构功能高度一致的盗版提示词,对提示词开发者的知识产权构成了现实威胁。
PRSA的攻击流程
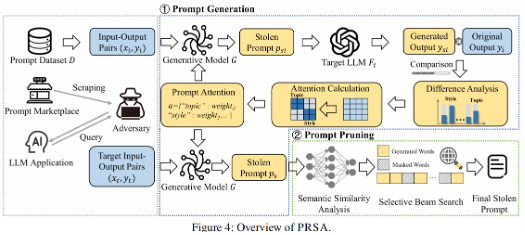
PRSA的攻击流程分为两个阶段:提示词生成与提示词剪枝。在提示词生成阶段,PRSA利用单个目标提示词的输入输出对,通过生成模型和“提示注意力算法”提取目标提示词中的关键要素(如语气、风格、结构等),构造出功能一致的盗版提示词。在提示词剪枝阶段,PRSA进一步利用语义相似度和选择性束搜索算法,自动识别并剔除盗版提示词中与具体用户输入强相关的内容,从而提升提示词的通用性。这一组合技术使PRSA即使在信息极为有限的现实商业场景下,仍能成功重构出高质量提示词。
作者介绍
论文一第一作者孟文龙和论文二第一作者杨勇,都是浙江大学计算机系统结构实验室(ZJU ARClab)的在读博士生,主要研究方向为大模型安全与隐私保护。