

喜讯!ARClab团队论文再次被ASPLOS 2025录用
浙江大学计算机系统结构实验室(ZJU ARClab)与阿里云合作的研究成果“OS2G: A High-Performance DPU Offloading Architecture for GPU-based Deep Learning with Object Storage”于2025年1月被体系结构领域CCF-A类会议ASPLOS录用。该论文由陈文智教授指导,针对在深度学习应用中使用对象存储导致的主机CPU消耗过高的问题,提出了一种基于DPU卸载对象存储客户端的方案,并实现了DPU与GPU之间的直接数据传输。该方案探索了在深度学习场景中使用DPU的潜力,显著提升了应用程序性能,并有效减少了主机资源的消耗。
会议介绍

ASPLOS是 ACM 编程语言和操作系统架构支持国际会议,是跨学科计算机系统研究的顶级学术论坛,涵盖硬件、软件及其交互。会议主要关注计算机架构、编程语言、操作系统以及网络和存储等相关领域,是计算机体系结构的四大顶会之一,也是中国计算机学会(CCF)认定的体系结构领域的A类会议。
深度学习应用中使用对象存储导致高CPU开销的问题
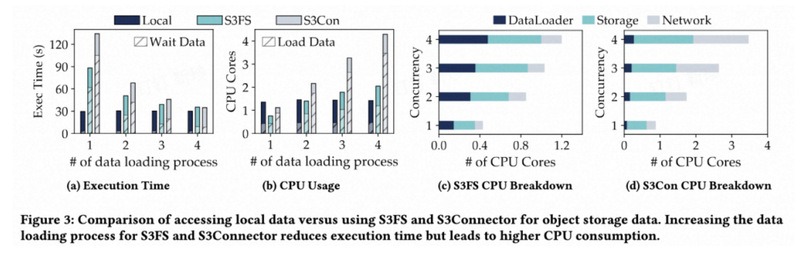
对象存储因其低成本和高可扩展性,越来越受到深度学习应用的青睐。然而,由于对象存储客户端涉及密集的数据处理和多次数据迁移,这会占用深度学习集群中的大量CPU资源。通过将对象存储客户端卸载到DPU上被认为是一种前景广阔的解决方案。然而,简单地将对象存储客户端卸载到DPU上会导致严重的性能下降。此外,仅仅卸载客户端并不能彻底解决冗余数据迁移问题,因为数据仍需从DPU传输到主机内存,再从主机传输到GPU,这一过程中会继续占用宝贵的主机资源。
高性能的DPU卸载对象存储服务架构
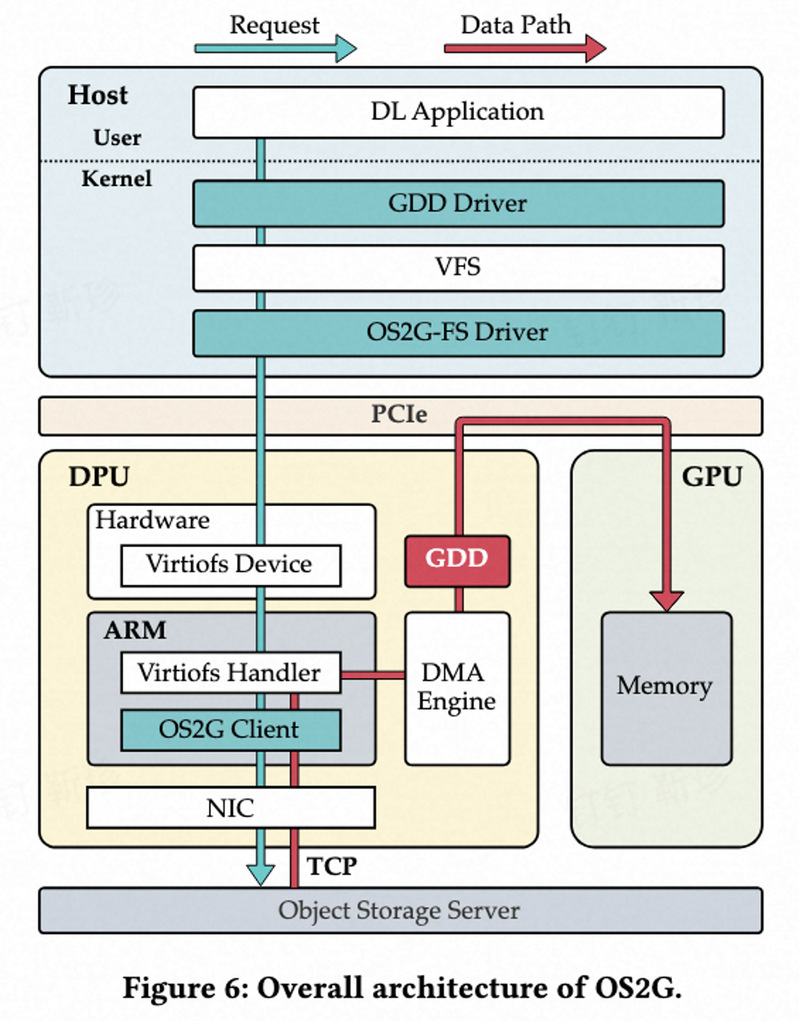
本文提出了OS2G,一种高性能的DPU卸载对象存储服务架构,旨在释放宝贵的CPU资源,同时为深度学习应用提供高效的存储服务。OS2G的核心理念是将对象存储客户端卸载至DPU,并实现DPU与GPU之间的直接数据传输。具体而言,我们设计了一款高性能的OS2G客户端,运行于DPU上,通过异步处理、预读技术和并发策略,提供高性能的对象存储服务。此外,我们提出了GPUDirect DPU(GDD)技术,以优化数据传输路径,支持DPU加速的存储系统与GPU计算系统之间的直接数据传输,从而完全绕过主机。实验结果表明,与S3FS和S3Connector相比,OS2G能够将ResNet18模型的执行时间分别缩短34.3%和50.4%,并显著降低CPU资源消耗,分别减少61.9%和57.7%。
作者介绍
论文第一作者靳珍为浙江大学计算机系统结构实验室(ZJU ARClab)在读博士生,阿里巴巴实习生,主要研究方向为面向AI的存储系统,存储虚拟化。