

喜讯!ARClab团队论文连续3年被HPCA录用
浙江大学计算机系统结构实验室陈义全、靳珍的论文“NVMePass: A Lightweight, High-performance and Scalable NVMe Virtualization Architecture with I/O Queues Passthrough”被体系结构领域CCF-A类会议HPCA’25录用。该论文由陈文智教授指导,提出了一种轻量化、高性能和可扩展的新型NVMe存储虚拟化架构。其核心思想是将NVMe I/O硬件队列直通给虚拟机,同时在NVMe SSD控制器Firmware里实现NRD(NVMe Resource Domain)机制以拦截非法I/O请求,实现安全隔离。该虚拟化架构具备了硬件加速卸载方案的高性能,同时有软件虚拟化方案的灵活性。
会议介绍

High Performance Computer Architecture(HPCA)是由IEEE举办的计算机体系结构/高性能计算领域最重要的学术会议之一,与ASPLOS, ISCA, MICRO并称为计算机体系结构领域的“四大顶会”。
现有NVMe存储虚拟化方案面临的挑战
目前主流的存储虚拟化技术可以分为软件方案和硬件辅助两大类。软件方案通过主机软件将NVMe设备虚拟化,而无需在硬件上增加额外的功能。然而,现有的软件型方案存在严重的性能下降或CPU开销过大的问题。为了解决性能问题,出现了SPDK vhost-NVMe等基于轮询的方案,利用独立的CPU核来处理I/O请求来提高性能,但需要消耗的宝贵CPU资源。硬件加速方案在硬件层面复制PCIe功能,为不同的VM呈现NVMe设备,使得VM能够绕过主机软件栈,直接访问硬件资源。因此,这些方案可以在不消耗额外CPU资源的情况下实现高性能。 然而,硬件辅助解决方案需要专用硬件进行NVMe虚拟化,这会带来额外的成本和硬件设计复杂性。
新型NVMe I/O队列直通虚拟化架构
本文提出了一种新型轻量级、软硬件协同设计的NVMe 直通虚拟化架构NVMePass,旨在实现高性能、零CPU开销,同时保持高可扩展性。NVMePass的关键思想是虚拟机的NVMe I/O队列直通和安全隔离机制。我们设计了一个新的I/O队列直通框架,使虚拟机能够直接访问硬件I/O队列,避免了软件虚拟化的高CPU开销挑战。为了解决直通后安全性的挑战,我们提出了一种NRD机制来拦截非法的 NVMe I/O请求。
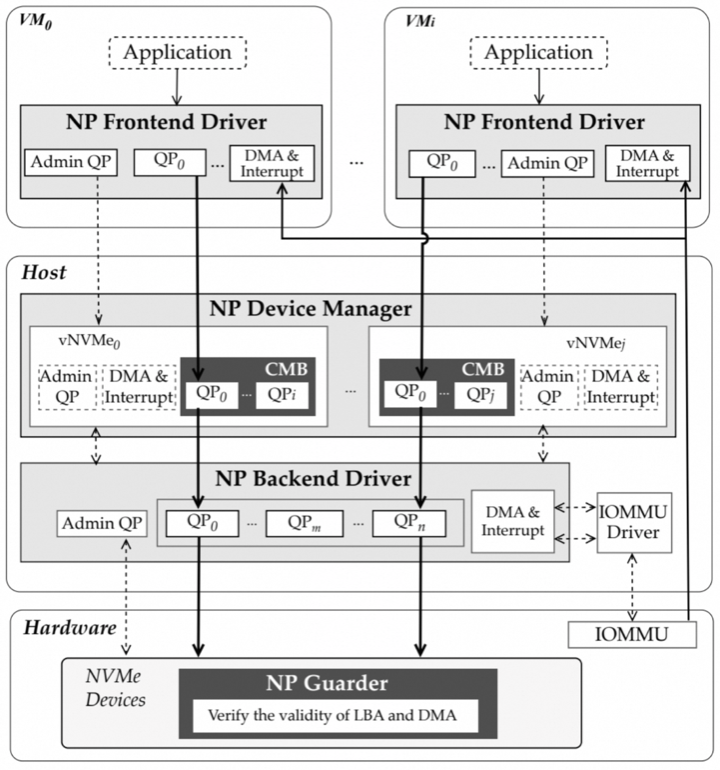
NVMePass有两个关键而独特的设计:(1) I/O 队列直通框架,(2) 直通安全隔离机制。队列直通实现原理,是通过在虚拟化NVMe设备中创建虚拟控制器内存缓冲区 (CMB) 和自定义页面错误处理程序来实现VM和物理设备的I/O队列之间建立直接地址映射。安全隔离是在NVMe控制器固件中实现NRD资源域机制,以拦截非法的NVMe I/O请求。NVMePass提供接近原生硬件的性能。除了I/O队列直通之外,NVMePass还支持直接内存访问 (DMA) 和VM中断重映射,而无需虚拟机管理程序参与,从而消除了虚拟化开销。实验结果表明,NVMePass可以提供与VFIO相当的性能,IOPS可达VFIO的 100.1%-100.5%。此外,与SPDK-Vhost相比,NVMe在运行150台虚拟机时延迟降低了40.0%,在实际应用中运行100台虚拟机时OPS性能提升了68.0%。
作者介绍
论文作者陈义全、靳珍为浙江大学计算机系统结构实验室(ZJU ARClab)的博士生,主要研究方向为智能计算系统架构。