

喜讯!陈文智教授团队论文被顶级会议ASPLOS录用
浙江大学计算机系统结构实验室(ARClab)在读博士生陆涛,硕士生陈于勋的论文“BatchZK: A Fully Pipelined GPU-Accelerated System for Batch Generation of Zero-Knowledge Proofs”于2024月10月被体系结构领域CCF-A类会议ASPLOS录用。该论文由陈文智教授和王总辉老师指导,提出了一个完全流水线化的 GPU 加速系统,用于批量生成零知识证明。该系统设计了一种流水线方法,使每个 GPU 线程能够连续执行其指定的证明生成任务而不会闲置。其次,该系统还采用动态加载方法加载证明生成所需的数据,从而减少了所需的设备内存。此外,多流技术可以实现数据传输和 GPU 计算的重叠,从而减少主机和设备内存之间数据交换造成的开销。
会议介绍

ASPLOS 是 ACM 编程语言和操作系统架构支持国际会议,是跨学科计算机系统研究的顶级学术论坛,涵盖硬件、软件及其交互。会议主要关注计算机架构、编程语言、操作系统以及网络和存储等相关领域,是计算机体系结构的四大顶会之一,也是中国计算机学会(CCF)认定的体系结构领域的A类会议。
现有GPU加速零知识证明系统中存在的问题
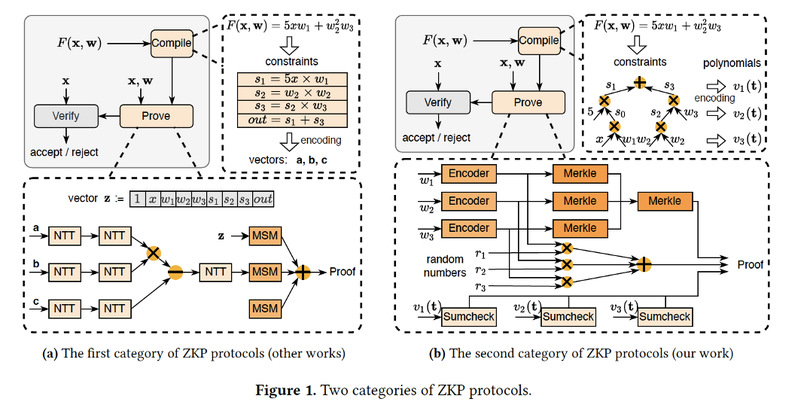
现有的 GPU 加速系统仅探索了如何高效地生成单个证明,目的是减少证明生成延迟。这些系统在单个证明生成上花费了过多的 GPU 资源,未能优化批量生成的整体吞吐量。提高吞吐量对行业至关重要,因为这意味着每单位时间可以生成更多的证明,从而带来更大的经济效益。此外,这些系统仅涵盖依赖于 NTT 和 MSM 等昂贵计算模块的 ZKP 协议。然而,最近的ZKP 协议越来越多地采用成本效益高的模块来生成证明,例如Sumcheck协议、Merkle 树和线性时间编码器 。这些成本有效模块的计算过程与NTT和MSM完全不同。因此,以前的系统无法应用于以这些成本有效模块为主导的ZKP协议。
全流水线的GPU加速零知识证明架构
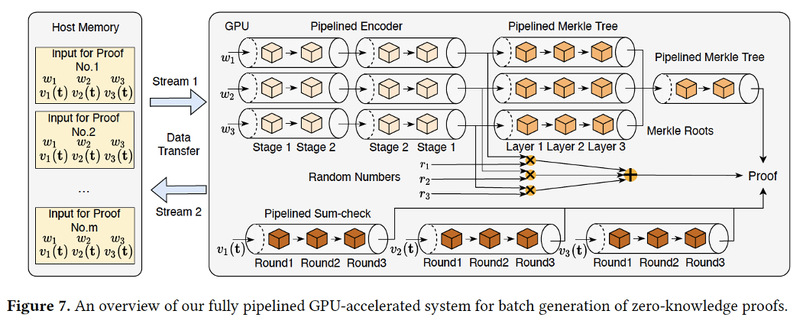
本文提出了一种全流水线的GPU加速零知识证明系统。首先,我们使用流水线技术来提高 GPU 上三个计算模块的吞吐量:Merkle 树、Sumcheck协议和线性时间编码器。然后,我们将这些组件组合在一起,用于批量生成零知识证明。通过采用最近的高效 ZKP 协议并提供合适的 GPU 资源分配方案,我们的系统与现有的GPU加速系统相比实现了 259.5 倍的吞吐量。我们将我们的系统部署在可验证的机器学习应用中,其中我们的系统每秒为以 CIFAR-10 图像为输入的 VGG-16 模型的预测生成 9.52 个证明,首次成功实现该领域的亚秒级证明生成。
作者介绍
论文第一作者陆涛,第二作者陈于勋为浙江大学计算机系统结构实验室(ZJU ARClab)的在读学生,主要研究方向为高效零知识证明技术。