

ARClab博士生马哲论文被人工智能顶级学术会议AAAI 2024录用
浙江大学计算机系统结构实验室(ARClab)博士生马哲的论文“Let All be Whitened: Multi-teacher Distillation for Efficient Visual Retrieval”于2023年12月被人工智能顶会Thirty-Eighth AAAI Conference on Artificial Intelligence(AAAI 2024)录用。该论文由陈文智、王总辉教授指导,提出了一种针对检索模型的多教师蒸馏框架,并利用白化(Whitening)技术消除模型间的分布差异,实现稳定的多教师融合。通过本研究的方法蒸馏得到的学生模型相比各个教师模型更加轻量,并且综合了多个教师模型的优势,性能优于单教师的结果。
会议介绍

AAAI是人工智能领域的国际顶级会议之一,也是中国计算机学会(CCF)认定地A类会议。该会议促进了人工智能的理论和应用研究,以及研究人员和实践者之间的知识交流。会议小组讨论和受邀演讲反映了影响全球人工智能发展的重大社会、哲学和经济问题。
检索模型与多教师蒸馏
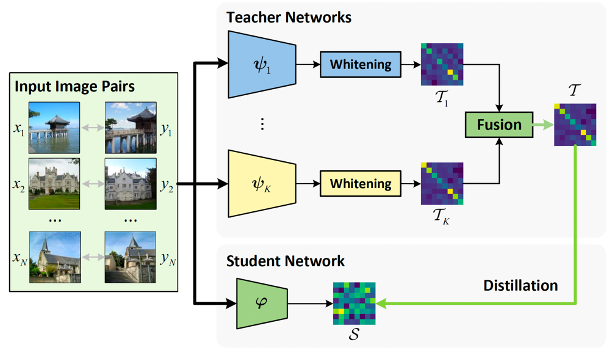
检索的目的是从大量的数据中搜索与给定查询最为相关的数据。例如,从全世界的建筑风景图像中搜索与“杭州西湖”相关的图像。随着人工智能技术,尤其是深度学习技术的发展,检索方法越来越依赖于大型深度神经网络。这引发了两个相互对抗的设计要素:其一是检索的准确性,即是否能够准确搜索到相关的内容,这要求检索模型对于数据的特征表示尽可能的准确;其二是检索的效率,实际的检索系统面临的是数以亿计的数据,在最短的时间内返回结果是必须的条件,这要求检索模型计算复杂度尽可能的低。本文通过多教师蒸馏,将现有模型作为“教师”模型,引导其训练一个更加轻量的“学生”模型,来综合研究这两项要素。一方面,现有工作已经提出并发布了大量的深度检索模型,综合已有模型的优势,通过多教师蒸馏将现有模型进行融合有望在性能方面进一步提升;另一方面,现有模型都基于深层的神经网络,计算复杂度较高,通过多教师蒸馏能够得到计算复杂度更低的模型。
多教师蒸馏的阻碍:模型间的分布差异

进行多教师蒸馏的一个隐含的前提是进行模型间的比较,以设计相应的方法对它们进行融合。我们发现,对不同的模型进行对比是一个非常困难的问题。如上图所示,两个模型按照相似度排序都能够正确检索到西湖美景,但明显模型#2输出的相似度值普遍更小,但我们能够因此判断,模型#2比模型#1更差吗?答案是否定的。
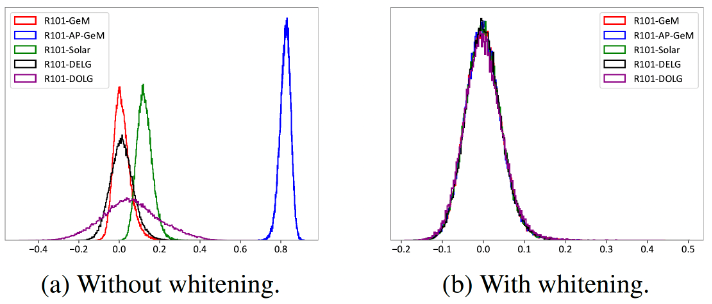
如上图所示,我们发现实际不同的检索模型都会输出不同范围内的相似度,并且相应分布的密度也不同。实际上,我们不能够因为一个模型输出了更大的相似度值,就认为它更为确信自己的判断结果,或是它判断得比其它模型更加准确。为了消除模型间分布差异的影响,我们利用白化技术统一教师模型的特征分布,实现神经网络的“车同轨,书同文”。在白化后的分布上,不同模型输出的相似度分布也变得完全一样,这表明模型因此以相同的尺度来做决策。
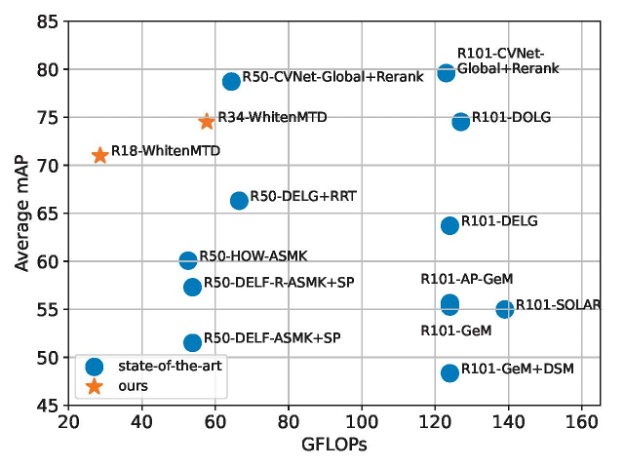
在百万级的图像和视频数据集上,通过白化的方法进行多教师蒸馏,我们可以仅仅用18或者34层的模型取得和SOTA方法50或者101层模型同水平的检索性能,同时大大降低计算复杂度。另外,我们提出的多教师蒸馏框架和白化方法简单有效,具有严格的理论保障,可以证明,白化后的模型将服从特定的分布,其具有确定的解析式。
作者介绍
论文第一作者马哲为浙江大学计算机系统结构实验室(ZJU ARClab)在读博士,主要研究方向为人工智能、数据安全等。