

参展云栖|OpenBuddy踏上新征程

在近日举行的2023阿里云栖大会上,人工智能AI+馆人头攒动,每个人都在谈论和试用各种各样的AI大模型应用。诞生于浙江大学 ARClab 实验室的OpenBuddy精彩亮相,ARClab团队展示了人工智能领域的最新成果和技术突破,以大模型为核心引领新一轮创新。OpenBuddy从创立开始秉持模型权重需要开放、公平的提供给所有人的理念,持续打造用户信任,积极参与构建公平、安全、可靠的AI社区,为人工智能领域的发展提供更深入的理论及实践依据。

此次受邀参展,OpenBuddy团队向大众展现了多规模、多语言、多维度的模型能力,以7B、30B、70B三种规模的模型应用作为展示案例,为参展的众多开发者提供参考。在展示过程中,研发团队与现场开发者积极互动,让观众亲身体验了OpenBuddy大模型的强大功能。通过于大模型的对话,观众们不仅感受到了人工智能技术的魅力,也对未来的人工智能发展及开源模型的演进充满了期待。

大会期间,ARClab实验室OpenBuddy团队的负责人陈天楚研究员还接受了媒体的采访。他表示,OpenBuddy基于多种开源基座如Mistral、Falcon和Llama2构建,结合了这些基座的优点,创建出了参数规模从30亿到1800亿的多个模型版本。并分享了OpenBuddy未来将持续优化和扩充模型,增强其认知能力,进一步推动其在多语言支持、智能问答、代码生成等认知领域的应用和发展。

OpenBuddy模型的核心优势
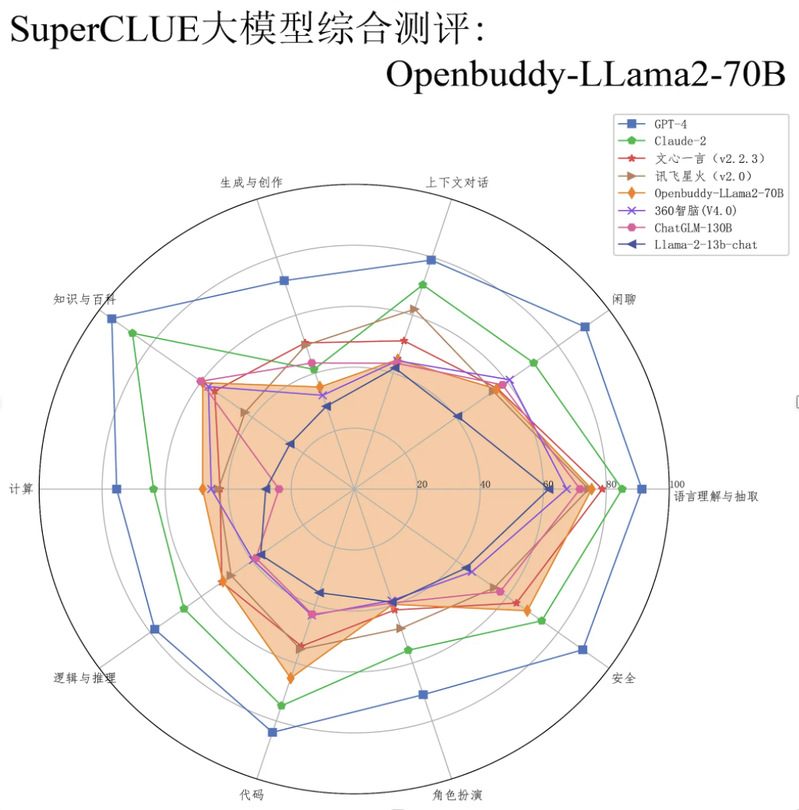
OpenBuddy模型主要强化了认知能力,包括逻辑推理、代码生成和深入的语言理解。它可以更深入地理解和回应用户的查询,处理复杂的逻辑和编码任务。此外OpenBuddy还具备中、日、韩、英、法、德的多语言能力,能够执行跨语言学习以及双语对话等任务。在多个基准测试中,包括CLiB和SuperCLUE,OpenBuddy模型在逻辑推理、代码生成、阅读理解等方面表现出色,性能接近顶尖的闭源模型。
OpenBuddy适配不同的硬件资源
OpenBuddy提供了不同规模的模型,从较小的30亿参数到大型的1800亿参数模型,可以根据用户的硬件资源进行合理选择。较小的3B、7B模型可以在移动设备、个人PC甚至边缘计算节点上运行。

OpenBuddy的应用潜力
OpenBuddy基于ARClab实验室在数据工程、自然语言处理、大模型训练方法以及算力调度架构方面的积累,并且在多个方面进行了深入研究并不断取得突破。
融合多种开源数据集及跨语言数据融合,并且自动化数据清洗、增强。
多种语言的语法、语言理解、通识数据;强化上下文感知的翻译任务及推理优化。
在训练方法中采用Flash-Attention 算子优化技术及DeepSpeed 分布式训练架构。
OpenBuddy模型由于其强大的认知能力,可以广泛应用于智能客服、在线教育、智能编程助手等场景,帮助企业和开发者提高效率和用户体验。除此之外,作为一个开源模型,OpenBuddy的权重完全开放下载,开发者可以进一步地使用特定场景的数据对其进行微调,获得垂直领域模型,这也是开源项目的优势。OpenBuddy团队欢迎各位研究者、大模型爱好者加入开源社区,共同分享基于OpenBuddy模型的调优和商业应用经验,与开发者共享共赢。