面向预训练语言模型下游迁移任务的隐私保护技术研究
预训练语言模型(Pretrained Language Models,PLMs)已经成为了自然语言处理(NLP)的主流方法。通过在大规模文本数据集上进行预训练,这些模型可以学习到丰富的语义信息和语境知识,之后通过微调(fine-tuning)的方式适配到具体的NLP任务上,显示出强大的性能。例如,BERT、GPT系列和RoBERTa等,它们在多种NLP任务上都取得了突破性的成绩。然而,随着模型规模的增大,微调的成本也变得越来越高。此外,这种方法在处理特定下游任务时,可能需要大量的标注数据,而这些数据在许多场合下并不容易获取。尽管这些问题在一定程度上得到了缓解,但预训练语言模型的使用仍然带来了一系列的隐私问题。因此,面向预训练语言模型下游迁移任务的隐私保护技术研究显得非常必要和紧迫。如何在保证模型性能的同时,防止敏感信息的泄露,减少计算和存储开销,是当前面临的重大挑战。本项目旨在对这些问题进行深入研究,并寻找有效的解决策略。
课题一:提示学习场景下的后门攻击研究
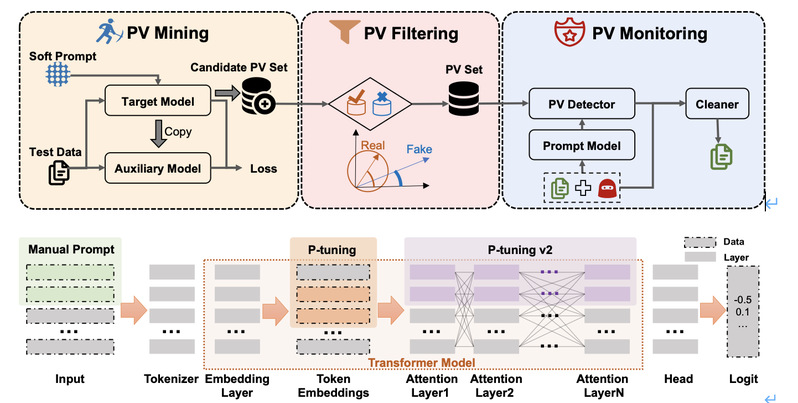
在NLP领域,随着预训练语言模型参数量逐渐增大,原本的“预训练-微调”范式受到挑战,微调大模型使其适应下游任务的成本愈发高昂。近年来,提示学习(prompt-tuning)作为一种新的部署语言模型到下游任务的范式被提出。提示学习冻结预训练模型的参数,在此基础上添加一些提示参数(soft prompt)。用户在用下游任务数据集训练大模型时只更新提示参数。提示参数的参数量不到原模型的1%,使得用户可以在消费级显卡上训练大模型。然而,提示学习这种范式非常容易受到预训练模型后门攻击的影响,攻击者将后门埋入预训练模型,然后将其发布在开源模型库上(如HuggingFace)。如果用户下载了这些带有后门的预训练模型,攻击者就可以通过在输入中添加后门触发单词(trigger)操纵下游模型的输出。由于提示学习冻结预训练模型参数的天性,这些隐藏在预训练模型中的后门极难在训练过程中被消除。本项目旨在研究一种预训练模型后门检测器并在冻结预训练模型参数的条件下消除后门。