

Efficient Cache Coherence Protocol for Many-Core Architectures
Abstract
As we enter the era of many-core, providing the shared memory abstraction through cache coherence has become progressively difficult. The de-facto standard directory-based cache coherence has been extensively studied; but it does not scale well with increasing core count. Timestamp-based hardware coherence protocols introduced recently offer an attractive alternative solution. In this paper, we propose a timestamp-based coherence protocol, called TC-Release++, that addresses the scalability issues of efficiently supporting cache coherence in large-scale systems.
Our approach is inspired by TC-Weak, a recently pro- posed timestamp-based coherence protocol targeting GPU architectures. We first design TC-Release coherence in an attempt to straightforwardly port TC-Weak to general- purpose many-cores. But re-purposing TC-Weak for general-purpose many-core architectures is challenging due to significant differences both in architecture and the programming model. Indeed the performance of TC-Release turns out to be worse than conventional directory coherence protocols. We overcome the limitations and overheads of TC-Release by introducing simple hardware support to eliminate frequent memory stalls, and an optimized life- time prediction mechanism to improve cache performance. The resulting optimized coherence protocol TC-Release++ is highly scalable (overhead for coherence per last-level cache line scales logarithmically with core count as opposed to linearly for directory coherence) and shows better execution time (3.0%) and comparable network traffic (within 1.3%) relative to the baseline MESI directory coherence protocol.
Overview

Figure 1. A simplified example of TC-Release with the execution of the code segment shown at the top.
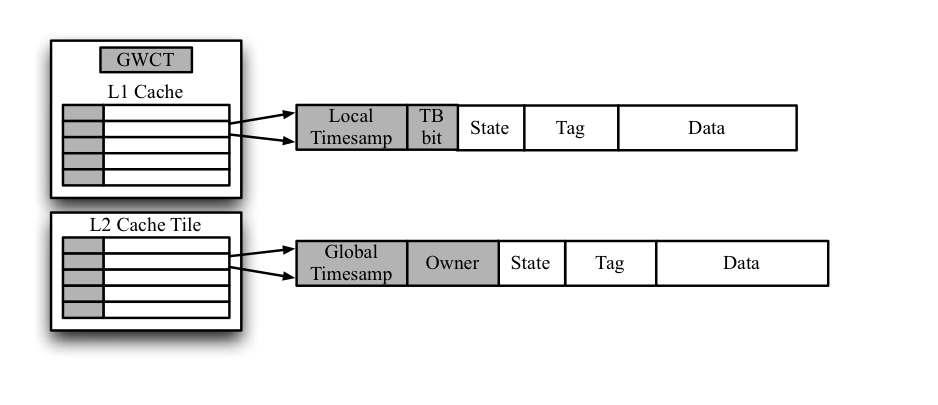
Figure 2 Hardware extensions for TC-Release
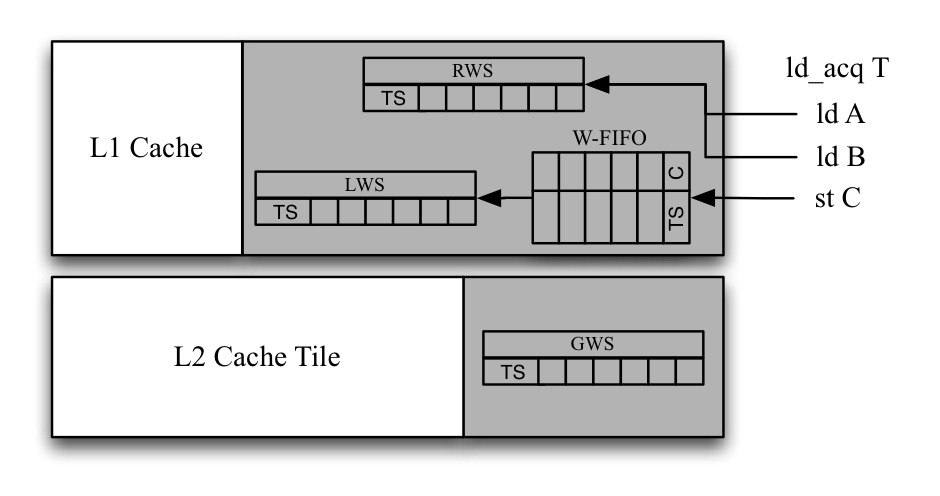
Figure 3 Hardware extensions for signature design in TC-Release++
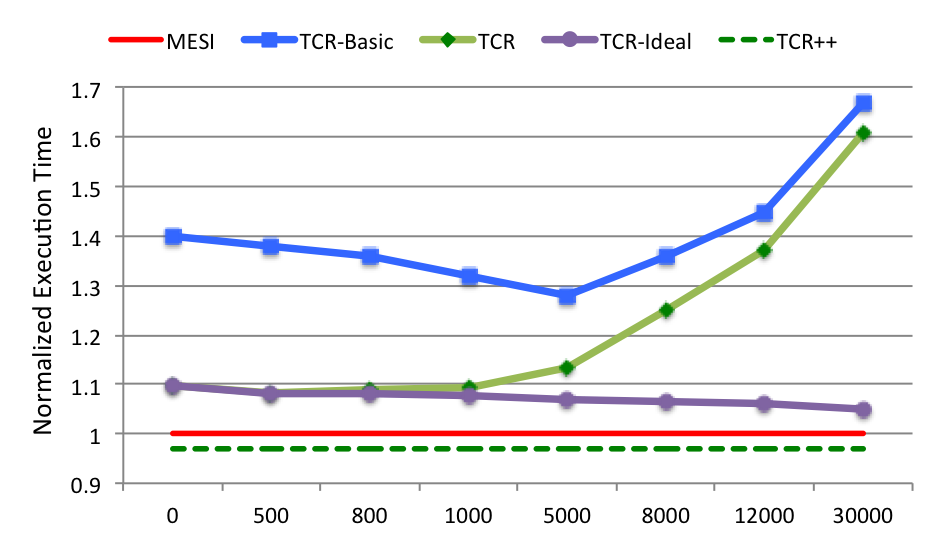
Figure 4 Normalized execution time of TCR, TCR- Basic, TCR-Ideal with various fixed lifetimes, with respect to baseline MESI directory protocol and TCR++.
Results
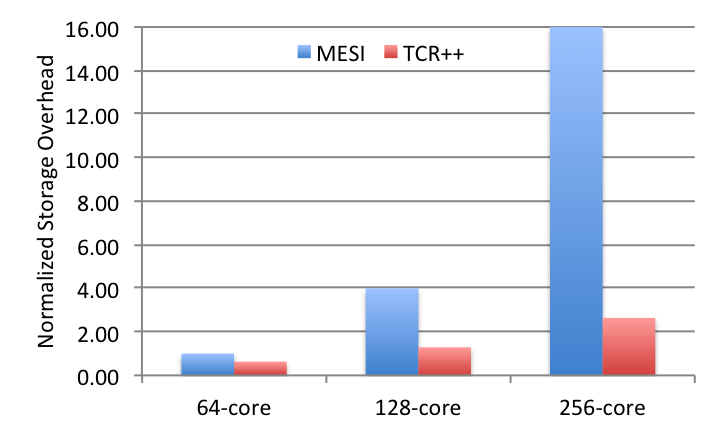
Figure 5 Storage overheads for cache coherence in TCR++ and MESI, with up to 256 cores.
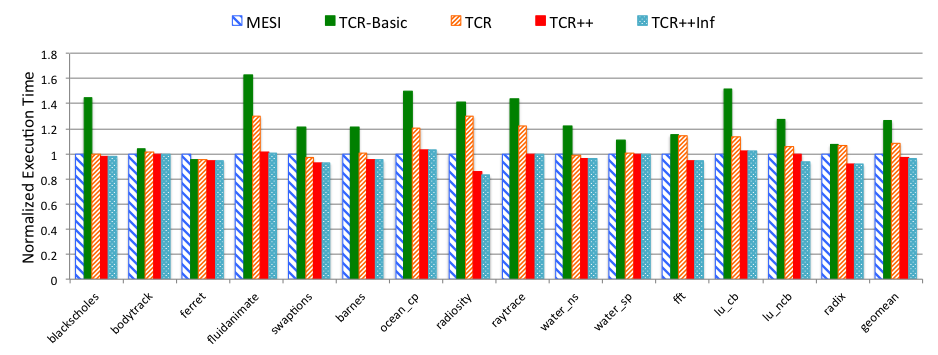
Figure 6 Execution time of all configurations, normalized to MESI.
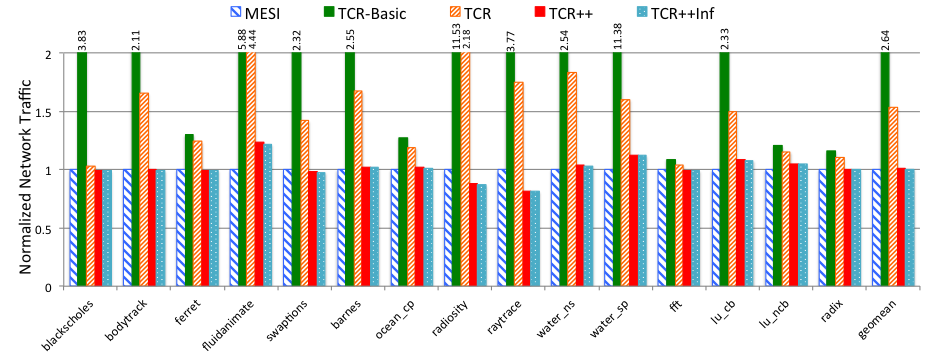
Figure 7 Network traffic of all configurations, normalized to MESI.
Members


Copyright Statement
This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder.